
Когда вы разрабатываете микросервис на Go, всё может казаться идеальным до тех пор, пока его не начинают использовать. После деплоя могут возникнуть проблемы с медленной работой приложения, повышенной нагрузкой на сервер или утечками памяти. Такие проблемы становятся трудными для обнаружения. И, чтобы вы не тыкались как слепой котёнок в попытке найти проблему, на помощь приходят метрики.
С метриками вы начинаете понимать, что отправка лога в Elastic занимает 200 мсек, при пяти тысячах запросах к сервису процессор нагружен на 100%. А ещё, со временем расход памяти возрастает.
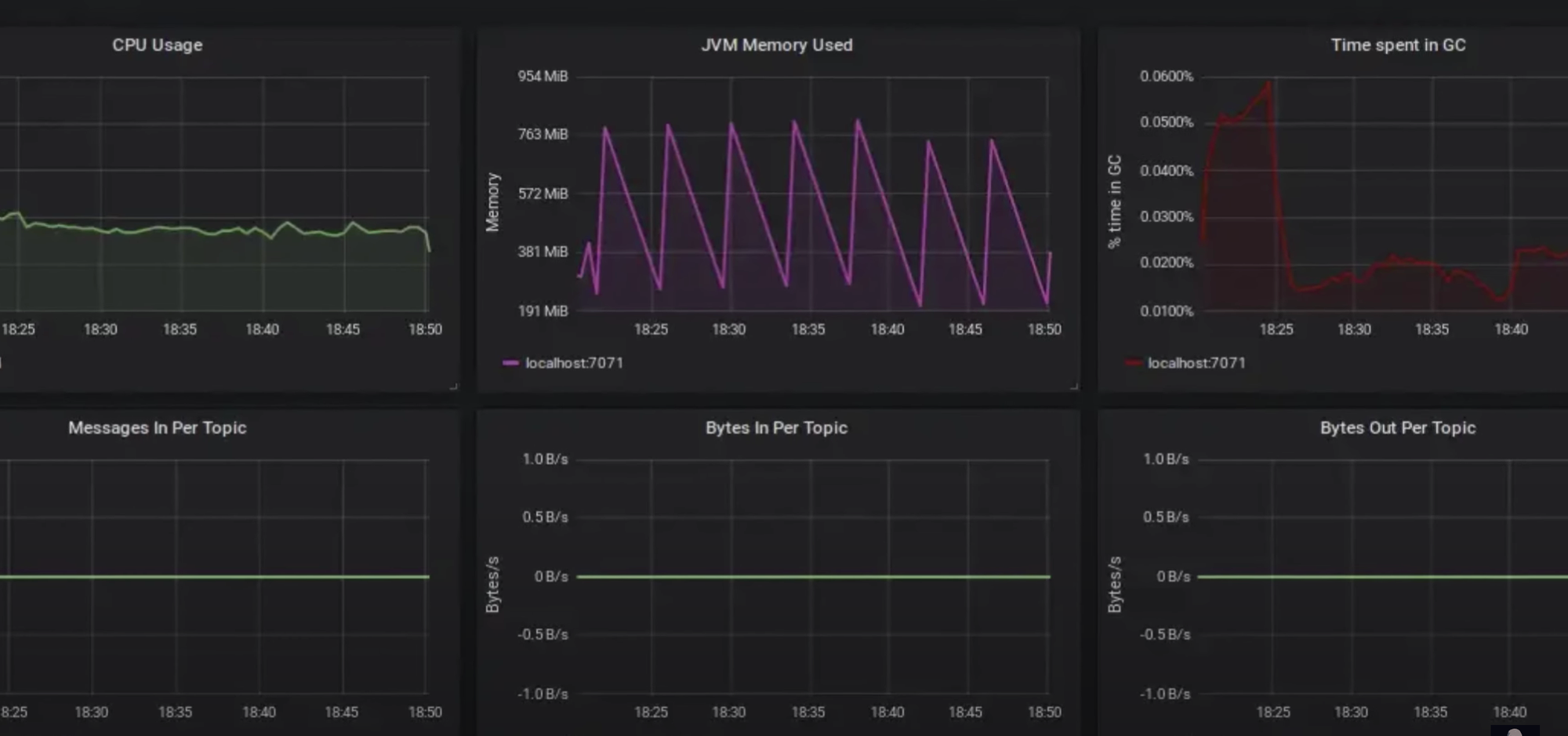
И, хотя вы видите специфичную для сборщика мусора “пилу”, после каждой чистки памяти расход всё равно больше, чем после предыдущей. И всё это вы понимаете благодаря метрикам.
Теория
Метрика – это численное значение какого-либо свойства вашей программы. Например, это время ответа сервиса, счётчик количества запросов или количество свободной памяти. Метрики являются ключевым инструментом для анализа и улучшения производительности приложения.
Для сбора, хранения и визуализации метрик необходима система мониторинга. Существует множество различных систем мониторинга, таких как Zabbix, Elastic и Prometheus. Каждая из них имеет свои особенности и методы сбора данных.
Системы мониторинга могут собирать метрики как пассивным (push), так и активным (pull) способом. Пассивный сбор данных происходит при помощи самого приложения, которое собирает и отправляет метрики в систему мониторинга. Активный способ заключается в том, что система мониторинга сама обращается к приложению и забирает метрики. Примером системы мониторинга с активным сбором данных является Prometheus. В этой статье мы поговорим именно о нём.
Почему Prometheus?
Prometheus - это достаточно лёгкая и популярная система мониторинга, с простым синтаксисом запросов и очень крутой системой хранения уже агрегированных данных.
Как я уже упоминал, Prometheus сам собирает метрики нужных приложений. Но кто их ему отдаёт? Экспортёры - это такие небольшие утилиты, которые предоставляют прометеусу специальный эндпоинт, через который он сможет собирать какие-то данные. Существует экспортёр для системных показателей сервера: нагрузка на процессор, количество свободной ОЗУ, нагрузка на сеть и т. д. Также существует, например, экспортёр для nginx, который считает количество запросов и их статусы.
В нашем случае мы будем внедрять экспортёр прямо в приложение, то есть, оно само будет способно выдать наружу эндпоинт, с которого прометеус сможет взять данные.
Постановка задачи
Что же будем покрывать метриками? Возьмём рекламный сервер, про который на канале уже есть целый плейлист.
У этого рекламного сервера есть адрес, открыв который запускается аукцион, и по его результатам происходит редирект на какой-то следующий адрес. И было бы круто этот адрес замониторить, чтобы узнать:
- Сколько запросов на него поступает?
- Сколько времени выполняется запрос?
- Какие HTTP статусы он возвращает? Всегда ли редирект, или когда-то 204 (пустой ответ)?
Что ж, задача поставлена, давайте откроем проект и перейдём к коду!
Настройка Prometheus
Давайте начнём с того, что поднимем докер образ прометеуса.
Ответвлюсь от clickhouse-stats, создам ветку prometheus и добавлю контейнер в файл docker-compose.yaml.
Также прокину prometheus.yml, чтобы настроить конфиги прометеуса. Остаётся лишь прокинуть порты, чтобы мы могли снаружи иметь доступ к прометеусу.
prometheus:
image: prom/prometheus:latest
volumes:
- ./prometheus.yml:/etc/prometheus/prometheus.yml
ports:
- "19090:9090"
Теперь создам в корне prometheus.yml, в который помещу пример конфига:
global:
scrape_interval: 15s # By default, scrape targets every 15 seconds.
evaluation_interval: 15s # By default, scrape targets every 15 seconds.
# A scrape configuration containing exactly one endpoint to scrape:
# Here it's Prometheus itself.
scrape_configs:
# The job name is added as a label `job=<job_name>` to any timeseries scraped from this config.
- job_name: 'prometheus'
# Override the global default and scrape targets from this job every 5 seconds.
scrape_interval: 15s
scrape_timeout: 15s
# metrics_path defaults to '/metrics'
# scheme defaults to 'http'.
static_configs:
- targets: ['localhost:9090']
# The job name is added as a label `job=<job_name>` to any timeseries scraped from this config.
- job_name: 'prometheus'
# Override the global default and scrape targets from this job every 5 seconds.
scrape_interval: 15s
scrape_timeout: 15s
# metrics_path defaults to '/metrics'
# scheme defaults to 'http'.
static_configs:
- targets: ['host.docker.internal:8082']
Конфигурация интуитивно понятная. В ней уже можете увидеть существующую джобу. Каждая из них по сути является отдельным микросервисом, и инстансов этих сервисов может быть много. Поэтому в targets вы можете указать не один, а несколько. А та джоба ‘prometheus’, которая уже существует, говорит о том, что собирает и экспортирует ещё и свои данные. Убедимся, что мы сделали всё правильно и запустим контейнер в командной строке:
docker compose up prometheus

Контейнер запустился успешно, давайте откроем адрес в Chrome, чтобы убедиться, что всё запущено. Видим Prometheus, можем посмотреть Status->Targets и увидеть, как он собирает с этой джобы метрики.
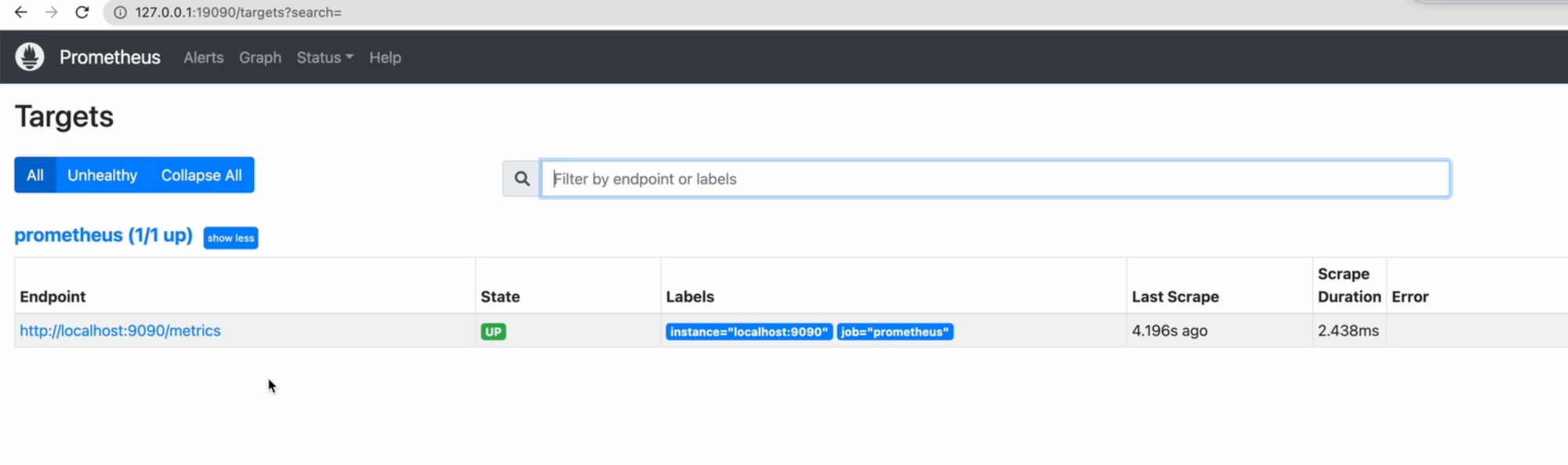
У неё state - up, то есть, всё получается. На самом деле, у прометеуса очень простенькая, но удобная админка. Разве что авторизацию, например, придётся делать самостоятельно через nginx или ещё как-то.
Вообще обычно для визуала используют систему отображения Grafana с удобными продвинутыми графиками, поддержкой разных источников данных, например, даже Clickhouse. Она отображает всё в виде удобных графиков и дашбордов. Но в этом видео для упрощения я буду работать без этой панели. Если же хотите узнать про неё, то можете посмотреть про это отдельный ролик.
Код
Запускаем сервер метрик
Чтобы приложение снаружи могло отдавать метрики, нам нужно поднять сервер экспортёра.
Для этого я для удобства создам пакет metrics, в котором размещу код запуска этого сервера.
Для нас, гоферов, существует официальная библиотека клиента, которую мы подключим в проект:
go get github.com/prometheus/client_golang
Давайте напишем функцию Listen, которая будет принимать host (address), будет создавать внутри мультиплексер. У него я зарегистрирую специальный паттерн “/metrics”, чтобы, когда к нему будут обращаться, обработкой занимался специальный Handler, который уже реализован в клиенте прометеуса. Он как раз реализован для сервера из стандартной библиотеки http.
Последнее, что остаётся - это запустить прослушивание на полученном адресе.
func Listen(address string) error {
//use separated ServeMux to prevent handling on the global Mux
mux := http.NewServeMux()
mux.Handle("/metrics", promhttp.Handler())
return http.ListenAndServe(address, mux)
}
Можно было бы сделать иначе. Существует пример в официальной документации, который не создаёт никаких мультиплексеров. Как видите, здесь в ListenAndServe во втором аргументе nil.
func main() {
flag.Parse()
// Create non-global registry.
reg := prometheus.NewRegistry()
// Add go runtime metrics and process collectors.
reg.MustRegister(
collectors.NewGoCollector(),
collectors.NewProcessCollector(collectors.ProcessCollectorOpts{}),
)
// Expose /metrics HTTP endpoint using the created custom registry.
http.Handle("/metrics", promhttp.HandlerFor(reg, promhttp.HandlerOpts{Registry: reg}))
log.Fatal(http.ListenAndServe(*addr, nil))
Но этот подход чреват тем, что регистрация эндпоинта “/metrics” происходит в глобальном мультиплексере. И, соответственно, если вдруг ваше приложение также всё это регистрирует, то есть также слушает глобальный мультиплексер, то вы можете получать метрики на неожиданном порту. Поэтому для того, чтобы всё точно изолировать, и чтобы на порту для метрик крутились именно метрики, я и создал отдельный мультиплексер.
Теперь я перейду в код, который запускает сервер и добавлю запуск сервера метрик в отдельной горутине:
go func() {
_ = metrics.Listen("127.0.0.1:8082")
}()
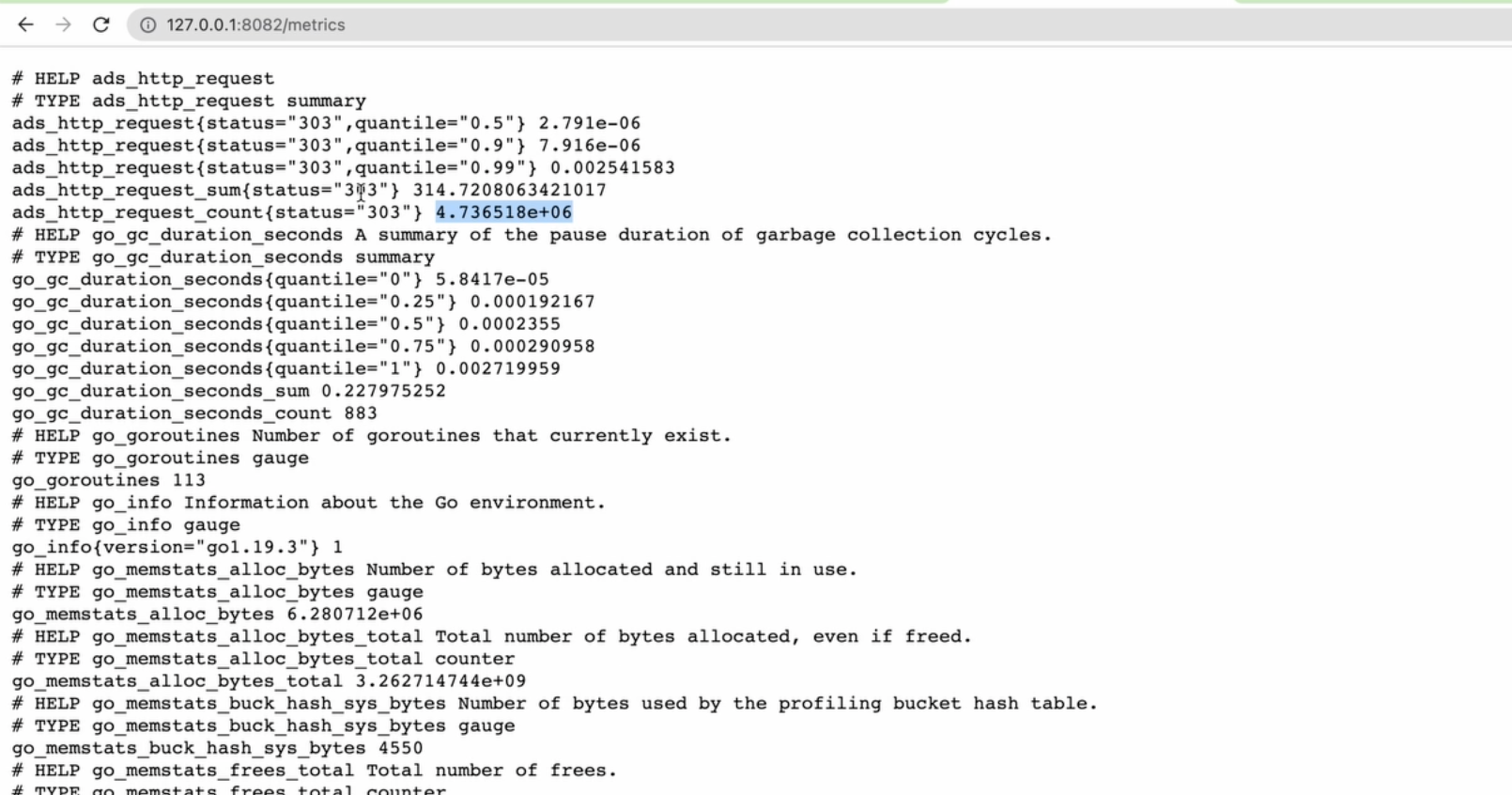
Опять же, для упрощения, я никак не буду обрабатывать ошибки. А слушать он будет на порту 8082, поскольку 8081 уже используется для самого сервера. Итак, код для запуска сервера метрик у нас готов, и мы можем запустить проект, и убедиться, что всё действительно запускается и работает. Я открываю адрес, на котором у меня размещен сервис метрик 127.0.0.1:8082/metrics.
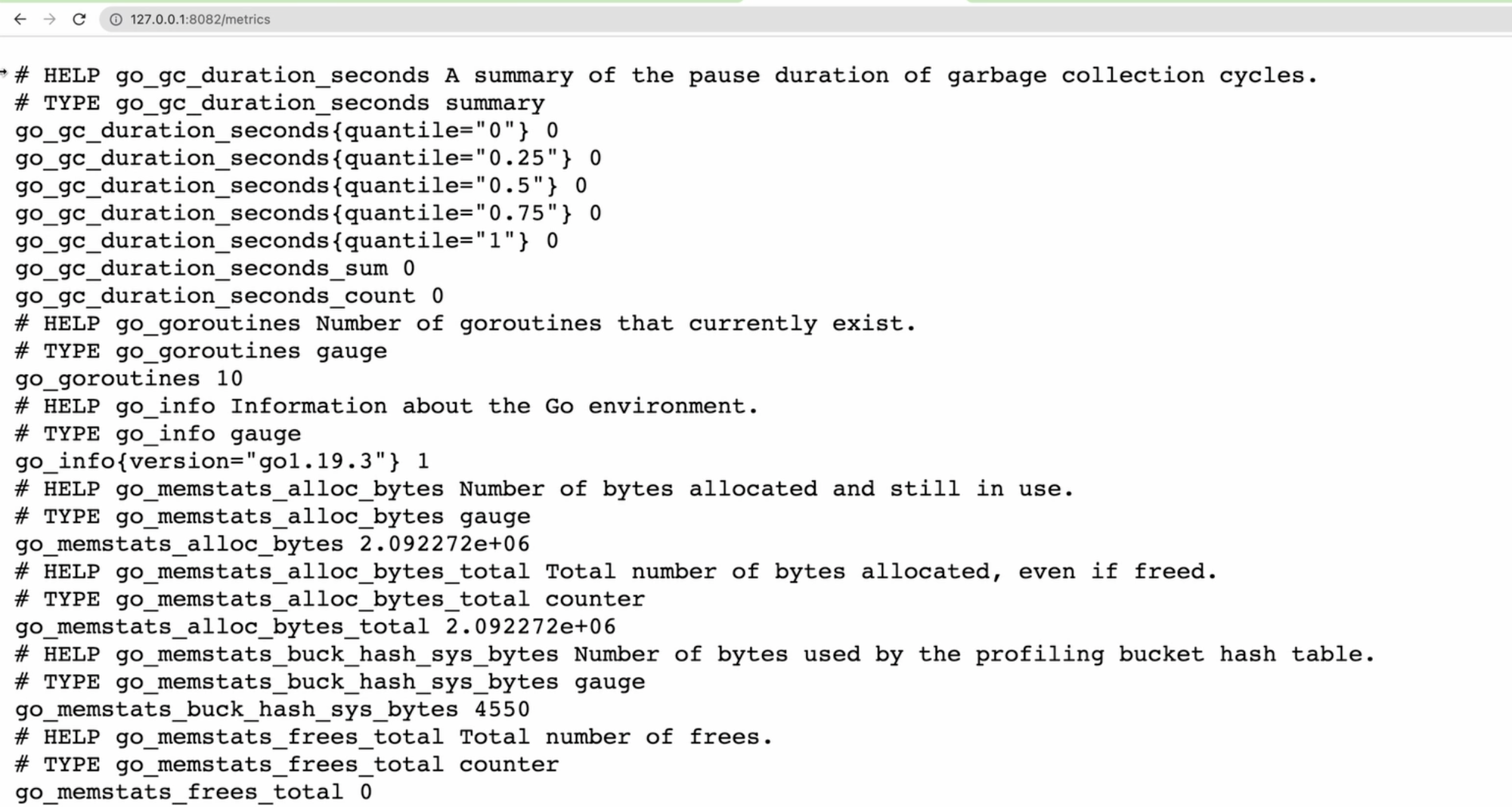
Как видите, здесь много метрик по умолчанию, потому что в стандартной конфигурации есть список так называемых коллекторов:
// Add go runtime metrics and process collectors.
reg.MustRegister(
collectors.NewGoCollector(),
collectors.NewProcessCollector(collectors.ProcessCollectorOpts{}),
)
Они могут уже собирать расход памяти, как часто запускается у вас garbage collector, как много памяти у вас выделяется, количество потоков и т.д. Таким образом, ваша задача сводится к тому, чтобы пополнить уже существующий список метрик вашими собственными, и они здесь как раз и появятся.
Получается дело за малым: экспортировать полезную информацию и подсоединить к приложению prometheus.
Добавляем сами метрики
Перейду в пакет ads и создам файл metrics.go, в котором расположу код. Давайте посмотрим, что нам нужно собирать. У нас уже есть небольшой эндпоинт, который как-то обрабатывает запрос, далее происходит редирект. Как мы уже обсудили с вами ранее, нам нужно ответить на три вопроса:
- Как часто обращаются к нашему эндпоинту?
- Как быстро наш эндпоинт отвечает?
- Какими именно статусами он отвечает? Очень важно не забывать про статусы, потому что они могут показывать разные логические пути вашего приложения.
Например, если наш рекламный сервер не может работать с мобильными устройствами, то он может без запуска всякого аукциона сразу вернуть ответ. Причём за очень короткое время. В то же время, для всех остальных будет запускаться аукцион, который работает дольше. Хотя у нас примитивный рекламный сервер, и он никуда не уходит, в реальных рекламных серверах можно обращаться во время аукциона к Redis, то есть делать работу, которая будет явно дольше 100 мкс. И если наложить результаты первого на второе, то ничего полезного из среднего арифметического мы не получим. Поэтому лучше так не делать и заранее разделять такие потоки информации.
Возвращаясь к нашей метрике: из всех поддерживаемых прометеусом типов данных нам идеально подходит Summary. Такой тип одновременно является и счётчиком, потому что количество добавленных данных подсчитывается; и в то же время это гистограмма, когда мы можем собирать длительность обработки запроса.

Поэтому я возвращаюсь к файлу metrics.go и добавлю переменную для Summary метрики. Самый простой способ дать прометеусу знать об этой метрике - зарегистрировать её с помощью пакета promauto. Я буду использовать именно ту функцию, в которой есть суффикс Vec, потому что я хочу указывать так же и метки для хранения статуса.
package ads
import (
"github.com/prometheus/client_golang/prometheus"
"github.com/prometheus/client_golang/prometheus/promauto"
"strconv"
"time"
)
var requestMetrics = promauto.NewSummaryVec(prometheus.SummaryOpts{
Namespace: "ads",
Subsystem: "http",
Name: "request",
Objectives: map[float64]float64{0.5: 0.05, 0.9: 0.01, 0.99: 0.001},
}, []string{"status"})
Настроим имя нашей метрики, которое состоит из Namespace, который всегда стоит в начале имени, подсистема Subsystem, и имя самой метрики. Давайте ещё пропишем специальную мапу Objectives, чтобы сохранять наши значения с учётом перцентилей. То есть, 0.5 нам даст медиану по времени ответа, 0.9 это будет 90-ый перцентиль и т.д. Так мы сможем более корректно с точки зрения статистики анализировать результаты. Например, если в среднем 50% ваших запросов выполняются за 100 мс, а 50% за 1 с, и в результате, по среднему арифметическому, вы получаете 500 мс, то это абсолютно бесполезный результат. Потому что у вас явно есть проблема, что запросы выполняются 1 секунду, а вы этого не видите. Вам как раз-таки нужно видеть этот всплеск, поэтому мы здесь указали Objectives. Последнее, что нам нужно здесь перечислить - это метки, и нашей меткой будет статус.
Таким образом, у меня получится по кривой на графике для каждого статуса.
И теперь я создам простенькую функцию, которая будет точкой входа для записи данных в эту метрику, а потом я буду вызывать её в обработчике запроса. Пусть она получает длительность запроса и наш статус.
func observeRequest(d time.Duration, status int) {
requestMetrics.WithLabelValues(strconv.Itoa(status)).Observe(d.Seconds())
}
Синтаксис такой, что сначала мне нужно перечислить метку, и, поскольку, эта функция принимает строки, а у меня статус хранится в int, я запущу Itoa, чтобы получить строку из нашего числа статуса. А Observe поможет нам записать длительность запросов в секундах с плавающей точкой (float64). Например, 100 мс он запишет как 0.1. А Prometheus и наша система визуализации всё это поймут.
Далее перейду в обработчик запроса, и в самом-самом начале создам переменную с именем start, в которую помещу текущее время на момент начала обработки. И сразу после с помощью defer буду вызывать функцию для сбора, которую мы только что написали.
start := time.Now()
defer func() {
observeRequest(time.Since(start), ctx.Response.StatusCode())
}()
В неё я буду передавать время, прошедшее со старта запроса и статус в нашем респонсе.
Замечание. Summary - это не самый быстрый тип метрик, потому что он считает квантили на клиенте. Поэтому, если у вас высоконагруженное приложение, то лучше используйте отдельно счётчики и гистограммы. Ведь в гистаграмме вы указываете некий бакет, который по сути и является счётчиком, то есть это диапазон. Когда приходят значения, входящие в этот диапазон, Prometheus просто увеличивает счётчик.
Вуаля, приложение готово. Перезапустим и попробуем несколько раз отправить запрос в постмане, чтобы понять как они отразятся на эндпоинте метрик.
После этого обновляю страницу с метриками в Chrome. А вот и наши результаты!
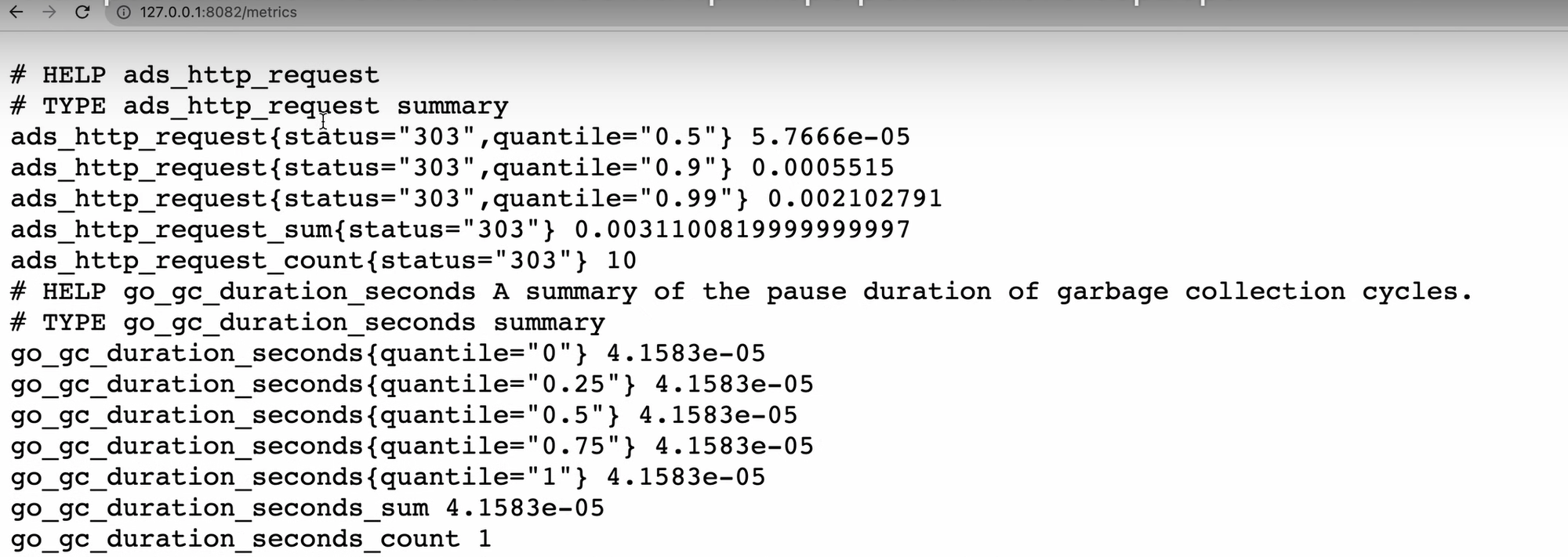
Он говорит, что я отправил через Postman 10 запросов, и все 10 раз он мне вернул статус 303, и это действительно так. Числа в не очень читаемом виде, но мы сейчас выведем их в самом прометеусе. Однако прежде чем это сделать, нам нужно сделать так, чтобы он начал опрашивать наше приложение.
Поэтому возвращаемся к конфигу прометеуса, где мы как раз и добавим нашу джобу для рекламного сервера. Скопирую уже существующую джобу, поменяю ей имя, адрес, который она должна слушать. Поскольку сервер я запускаю на локальном компьютере, а прометеус у меня работает в докере, я буду обращаться за метриками по адресу host.docker.internal, порт у нас 8082.
# The job name is added as a label `job=<job_name>` to any timeseries scraped from this config.
- job_name: 'ads_server'
# Override the global default and scrape targets from this job every 5 seconds.
scrape_interval: 15s
scrape_timeout: 15s
# metrics_path defaults to '/metrics'
# scheme defaults to 'http'.
static_configs:
- targets: ['host.docker.internal:8082']
Запущу Prometheus, чтобы он увидел новый конфиг. Теперь перехожу обратно в браузер, и в Targets должен появиться мой сервер, который Prometheus ещё не успел опросить.
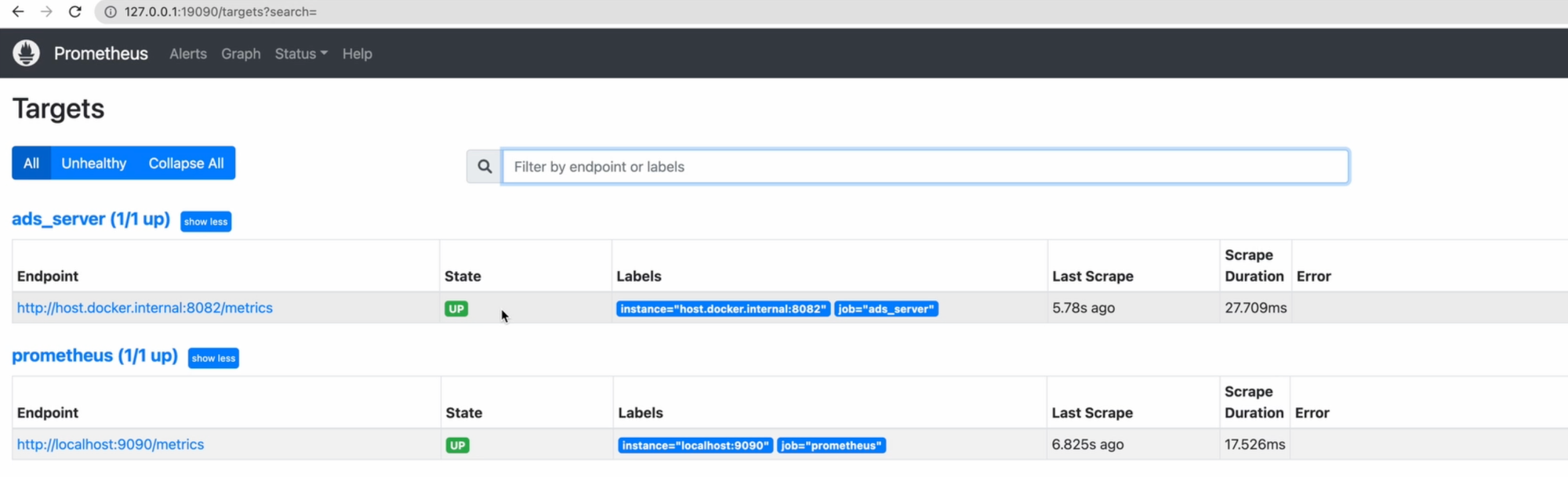
И, поскольку наш рекламный сервер уже имеет какие-то данные, мы можем их даже вывести. К счастью, сам прометеус и его внутренний интерфейс может выводить графы.
Визуализация
Здесь стоит упомянуть, что запросы прометеуса пишутся на специальном языке PromQL. Это очень простой язык, и сейчас вы сможете увидеть его синтаксис.
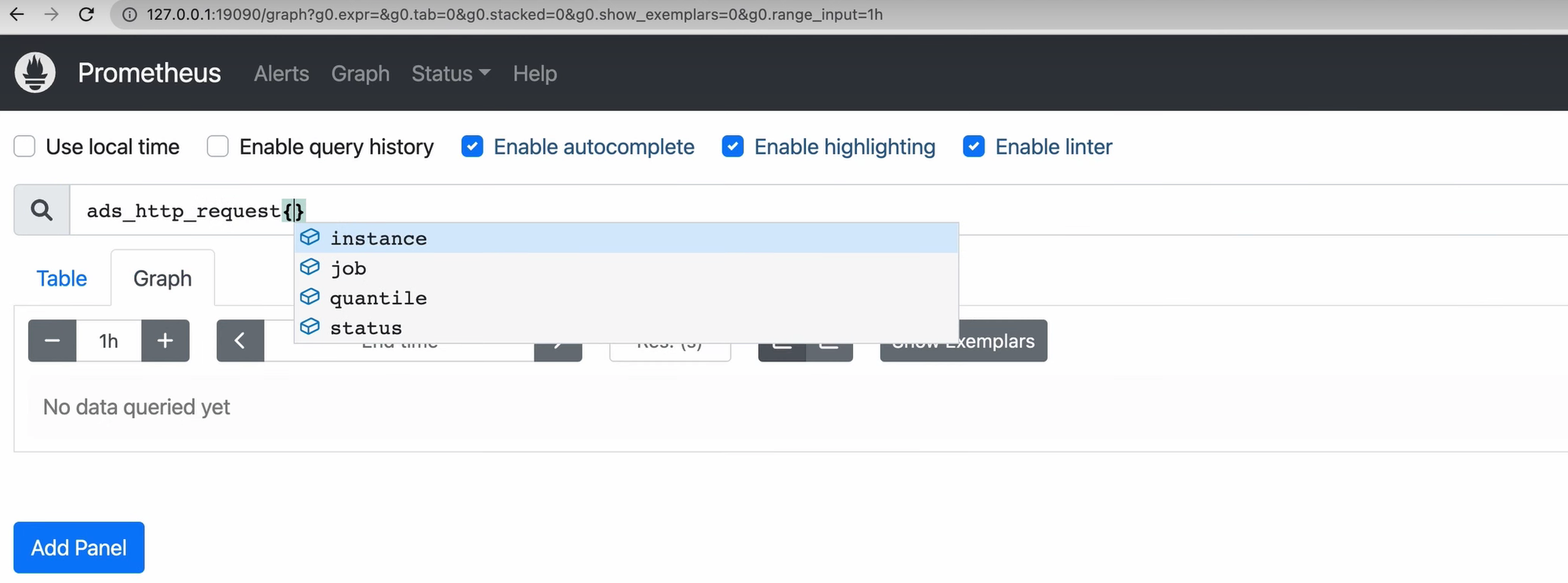
Здесь я пишу запрос, и его интерфейс уже сам подсказывает, какие у него должны быть параметры. Указываю квантиль:
ads_server_requests{quantile="0.95"}
После нажатия на Enter видим достаточно скучную прямую линию - нам даже не получится нагрузить сервер, отправляя запросы в постмане.
Нагрузочное тестирование с помощью bombardier
А теперь давайте под конец повеселимся! Воспользуемся утилитой, которая предназначена для нагрузочного тестирования. Ей я и хочу загрузить свой рекламный сервер. Установить её можно с помощью команды:
go install github.com/codesenberg/bombardier@latest
И остаётся её только запустить! Пускай она работает в 100 потоков целую минуту!
bombardier -c 100 -d 60s http://127.0.0.1:8081
Замечание. Конечно, проводить нагрузочное тестирование с той же машины, на которой запущен сервер, категорически неправильно. Но мы ведь веселимся!
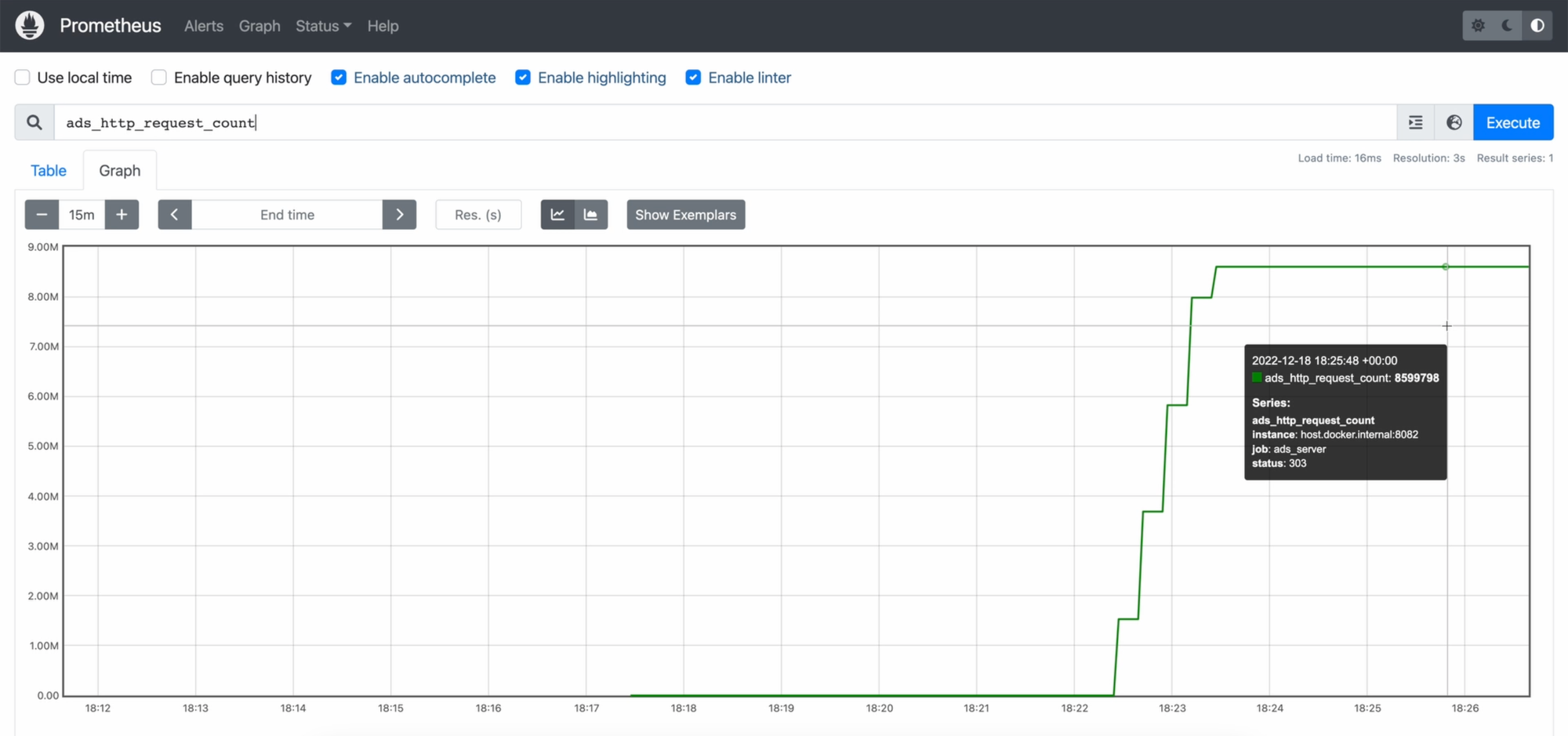
В браузере мы уже видим, что случилось 5 млн запросов.
Более того, когда bombardier закончит это делать, он тоже вернет статистику по времени ответа сервера, какие статусы он отдавал. Вдруг под нагрузкой ваш сервер отдаёт 502? Тогда вы сможете увидеть это засчёт bombardier, даже не глядя на метрики самого сервиса.

Смотрим на статистику - за это время было совершено более 8 млн запросов! Максимально сервер отвечал 76 мс, но в среднем обработка занимала меньше 1 мс. При этом единственный код ответа, который возвращал наш сервер, это 300-ые коды.
Возвращаемся в интерфейс прометеуса, и давайте попробуем теперь взглянуть на графики!
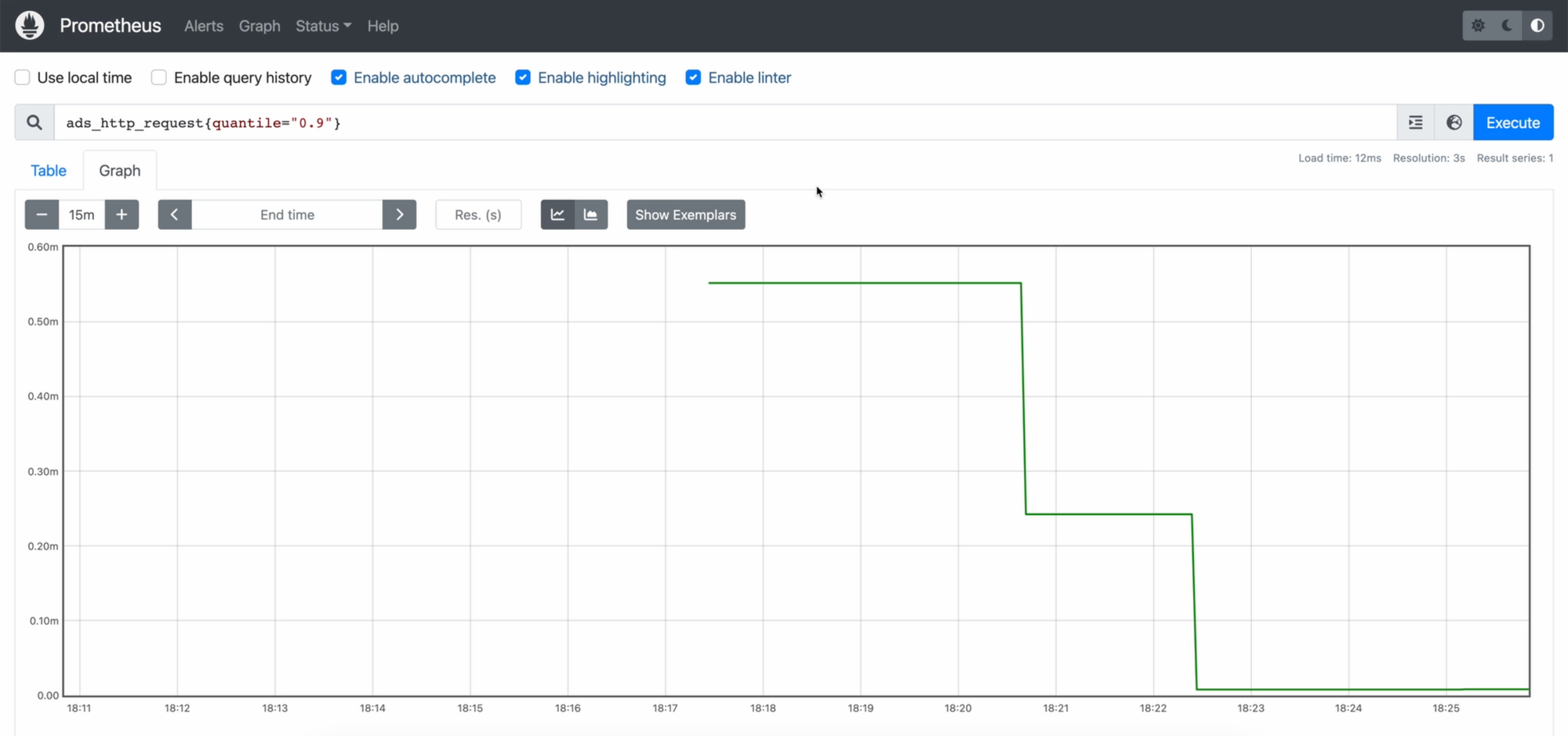
Время обработки запроса у нас - достаточно скучная метрика, потому что у нас ничего серьезного не происходит внутри самого сервера. Интересно может быть с количеством запросов, поэтому я сейчас выведу количество запросов в минуту. Если мы просто выведем ads_server_requests_count, то мы увидим кривую, которая в рамках одного запуска приложения всё время растёт, потому что это просто сумма всех запросов.
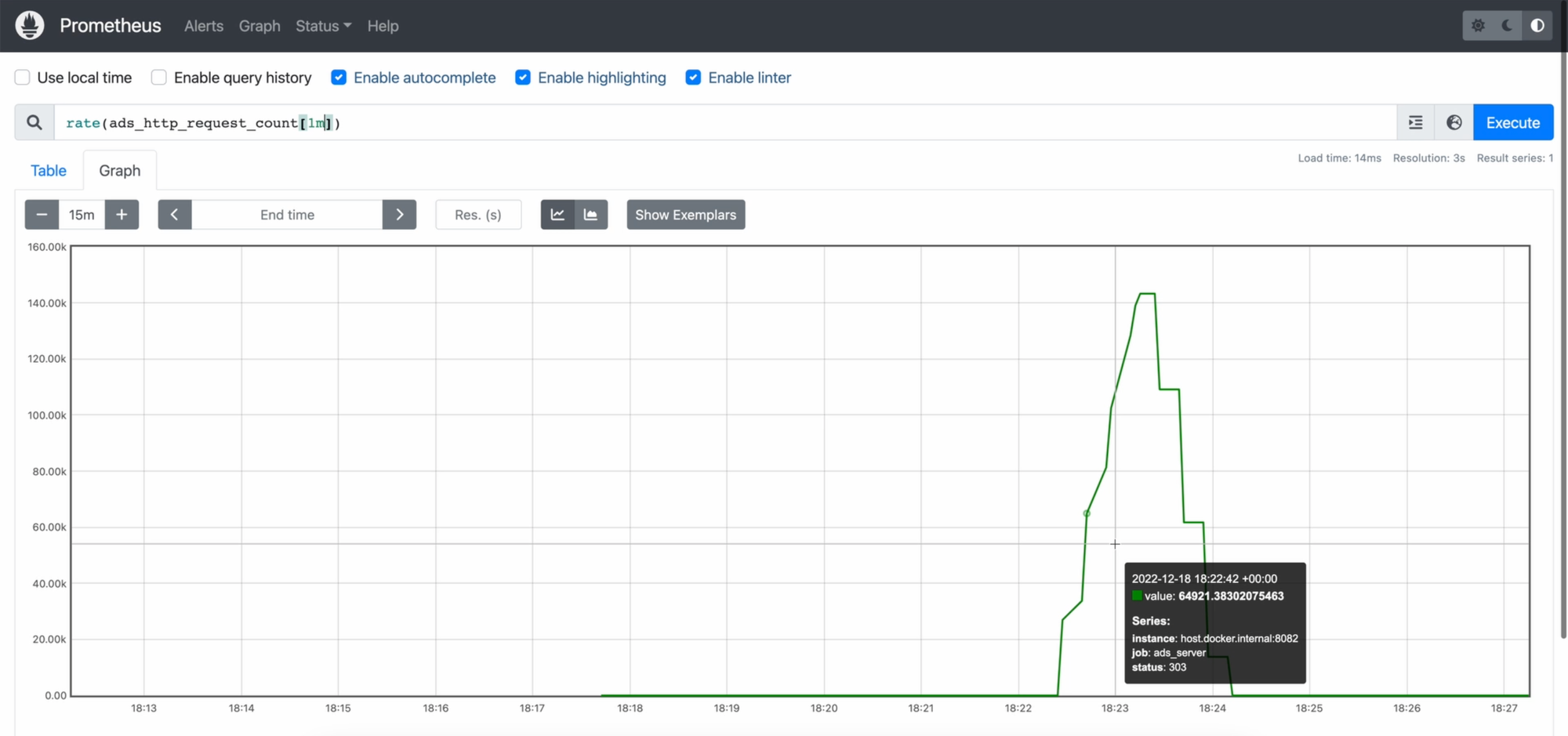
А нам нужен именно rate в минуту. Для него у прометеуса существует функция rate, в квадратных скобках будем указывать время, за которое нас интересует количество. Наш запрос будет выглядеть так:
rate(ads_server_requests_count[1m])
О, вот так уже становится немного интереснее.
Финал
Вообще, в реальном мире отдельно длительность запроса или количество этих запросов никогда не бывает полезным. Какая разница, если мы узнали, что за минуту наш сервер обработал 8.5 млн запросов? Он может обработать их, потратив всю память на системе или израсходовав все ресурсы процессора, как мы как раз-таки могли наблюдать в мониторинге системы. Или же процессор вообще не почувствует этой нагрузки.
Именно поэтому метрики всегда анализируют в совокупности с чем-то ещё: нагрузка на процессор, расход памяти и так далее. Например, как программа ведёт себя при 5000 запросах, сколько она примерно потребляет памяти, сколько процентов процессора при этом использует. Если ваш сервер нагружает процессор на 70% при 5000 запросах в секунду, то, наверное, это довольно много для него, и можно подумать над оптимизацией приложения. Вы сможете поставить себе цель, что при такой нагрузке процессор не должен нагружаться более чем на 50%. Вы как-то изменяете код, затем возвращаетесь к графикам и убеждаетесь, что на вход у вас поступает те же самые 5000 запросов, при этом метрика с нагрузкой процессора теперь не привышает 50%.
Обычно все эти метрики выводят на одном дашборде в системах вроде Grafana. Если хотите посмотреть, как создавать дашборды в Grafana, то обязательно переходите по ссылке с видео об этом.
Напомню, что полный код из данной статьи находится в репозитории.
Огромное спасибо, что дочитали до конца. Предсказуемого кода вам!