Grafana – установка, настройка алертов, интеграция Prometheus и ClickHouse

Как установить в Docker, как подключить Prometheus, как создать панель, как подключить ClickHouse и как настроить алерты
Grafana – это мощная система визуализации метрик.
В этой статье я покажу как её установить в Docker, как подключить в Grafana Prometheus, как создать панель в Grafana, как подключить ClickHouse в Grafana и как настроить алерты.
По ходу ролика покажу несколько практических подходов, которые упростят вашу работу с Grafana.
Что такое Grafana
Grafana – это система визуализации метрик ваших приложений. Когда вы что-то разрабатываете, важно следить за тем, что происходит внутри: насколько нагружен сервер, как быстро отрабатывают запросы. Да даже если у вас просто умный дом, то графана – отличный выбор для отображения статуса умной лампочки в умной спальне.
Grafana умеет выводить не только графики, но и таблицы, гистограммы, диаграммы, геокарты и ещё кучу других способов визуализировать ваши метрики.
Grafana может брать данные не только из прометеуса , но и из кликхауса , MySQL , InfluxDB или еластика . И кстати, в этом ролике (и статье) я покажу и прометеус, и кликхаус.
Прямо в графане, вы можете настроить и алерты, и сегодня я про них тоже расскажу.
А если вы не хотите арендовать собственный сервер, то у графаны есть даже облачное решение с весьма комфортным бесплатным тарифом.
Установка в Docker
По традиции, подопытным проектом будет рекламный сервер , о котором на канале есть целый плейлист .
Устанавливать графану мы будем через Docker.
Добавим контейнер в docker-compose.yml и запустим команду docker compose up.
services:
...
grafana:
image: grafana/grafana-oss:9.4.3
ports:
- "13000:3000"
volumes:
- grafana-data:/var/lib/grafana
volumes:
grafana-data:

Теперь мы можем открыть адрес 127.0.0.1:3000, ввести логин admin и пароль admin, и встретить успешно установленную графану!
Подключение Prometheus
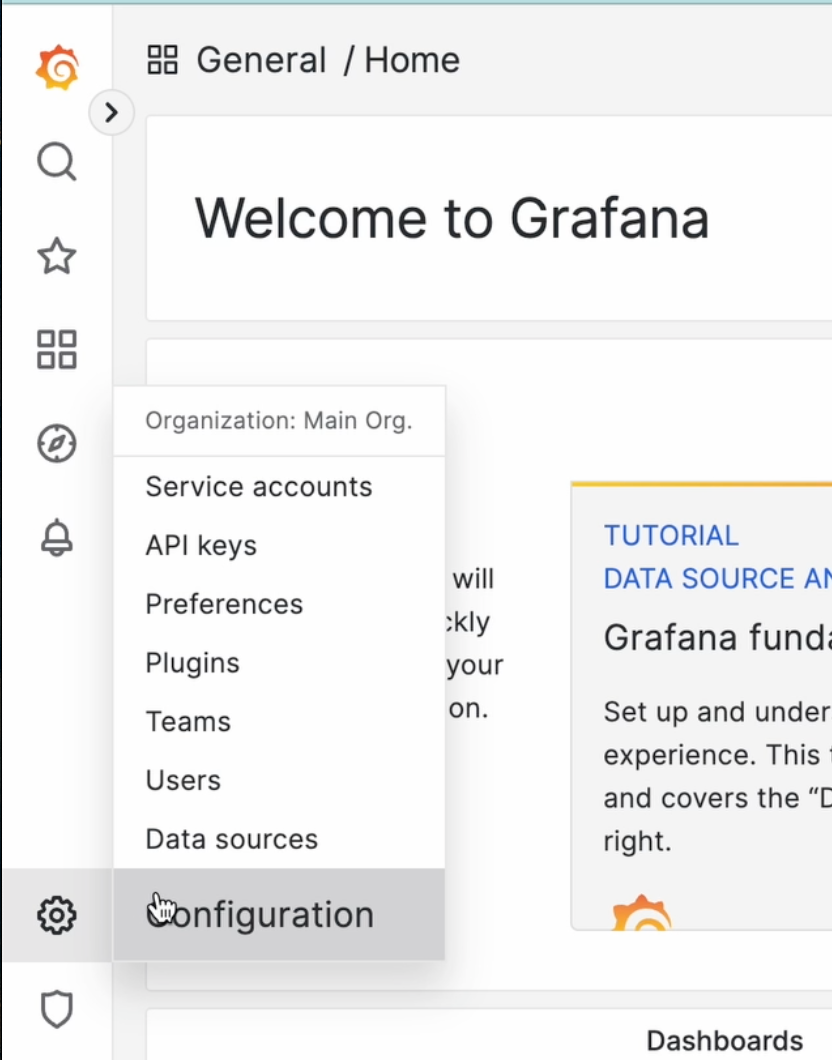
Теперь давайте подключим Prometheus, который находится в соседнем контейнере. Перейдем в Настройки -> Data Sources (источники):
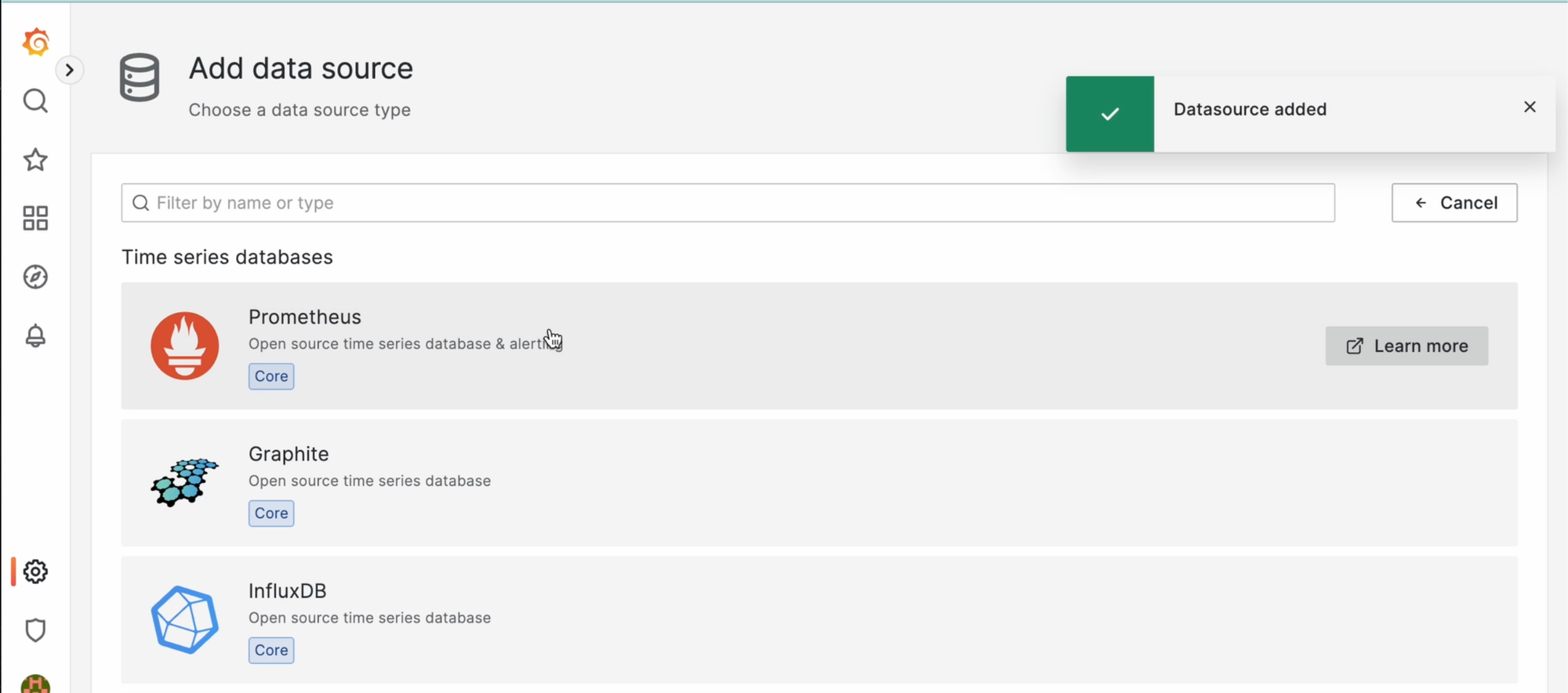
Затем нужно добавить новый источник и выбрать Prometheus:
Поскольку у нас всё это находится в одном docker-compose, то мы можем обращаться к прометеусу прямо через хост prometheus:9090:
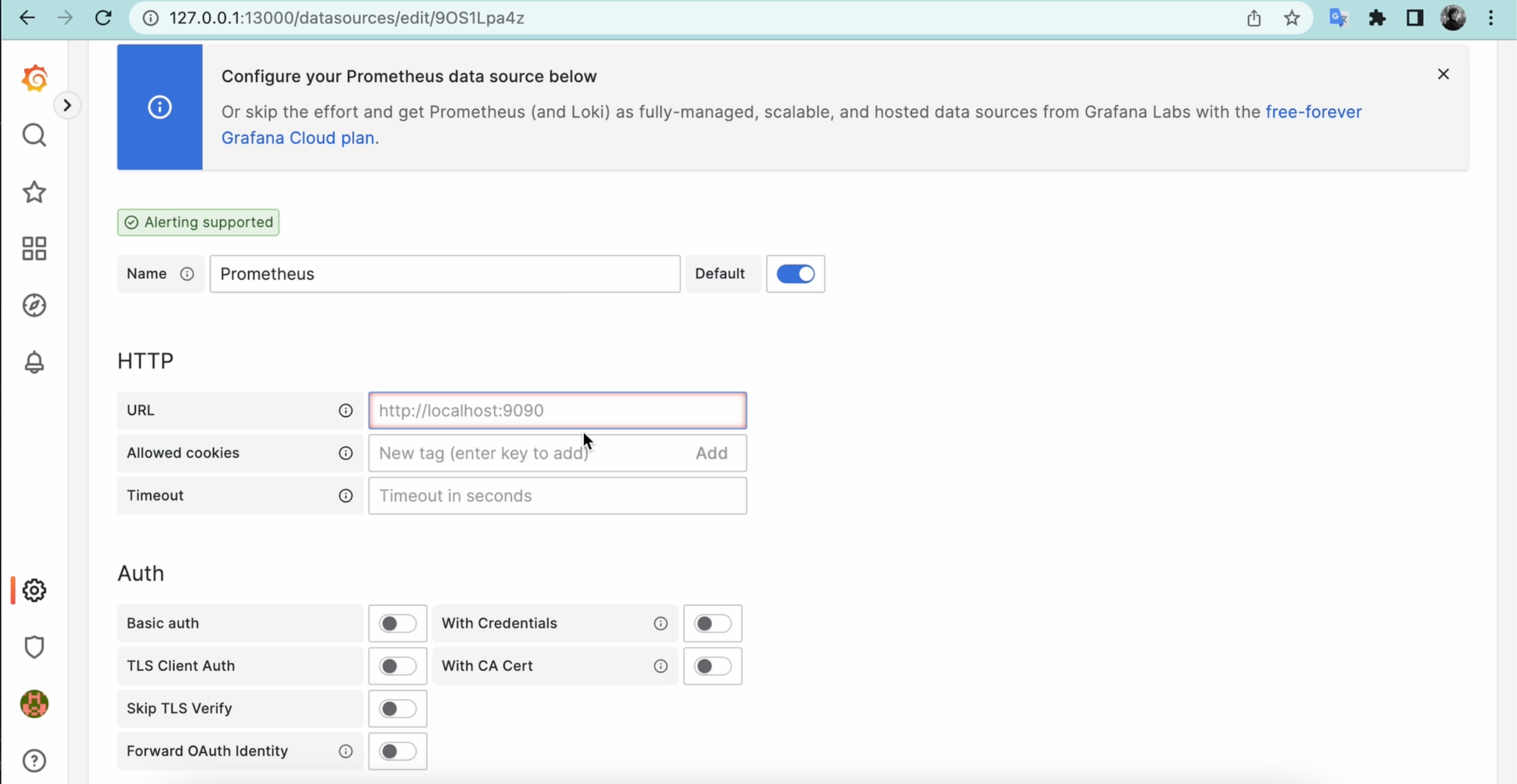
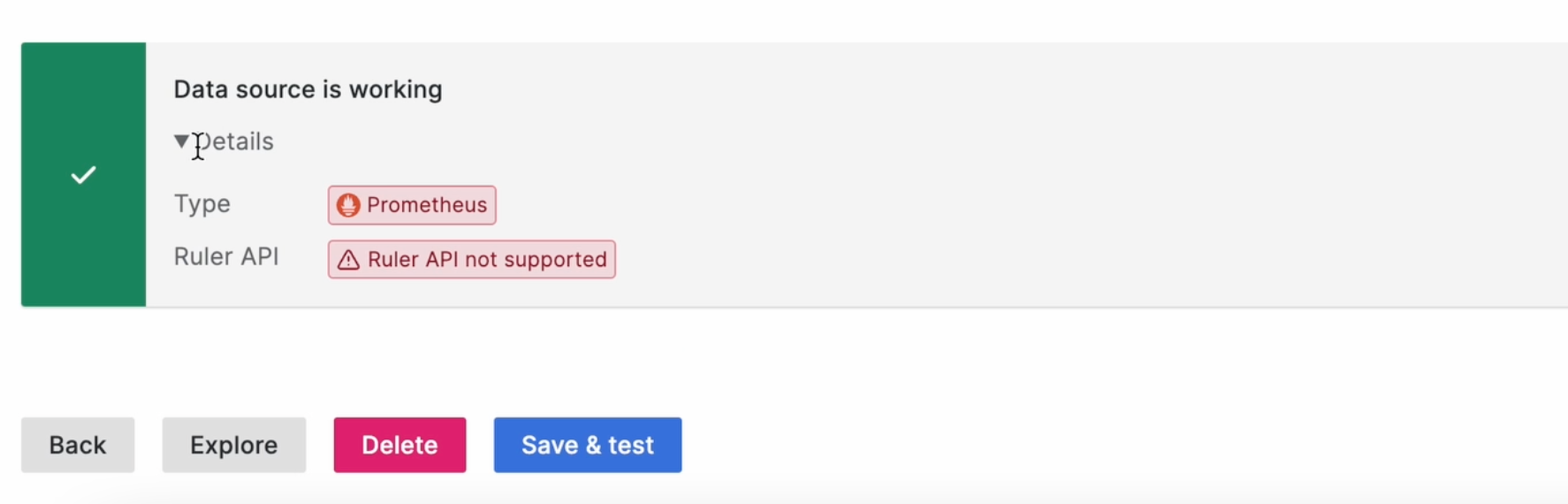
Остальное можно оставить как есть. Теперь кликаем “Save & Test”, и видим, что новый источник работает!
Вывод метрик
Time series
Давайте начнём с того, что выведем частоту запросов к ротатору. Для этого нужно создать новый Dashboard – место, где мы будем аккумулировать все метрики ротатора:
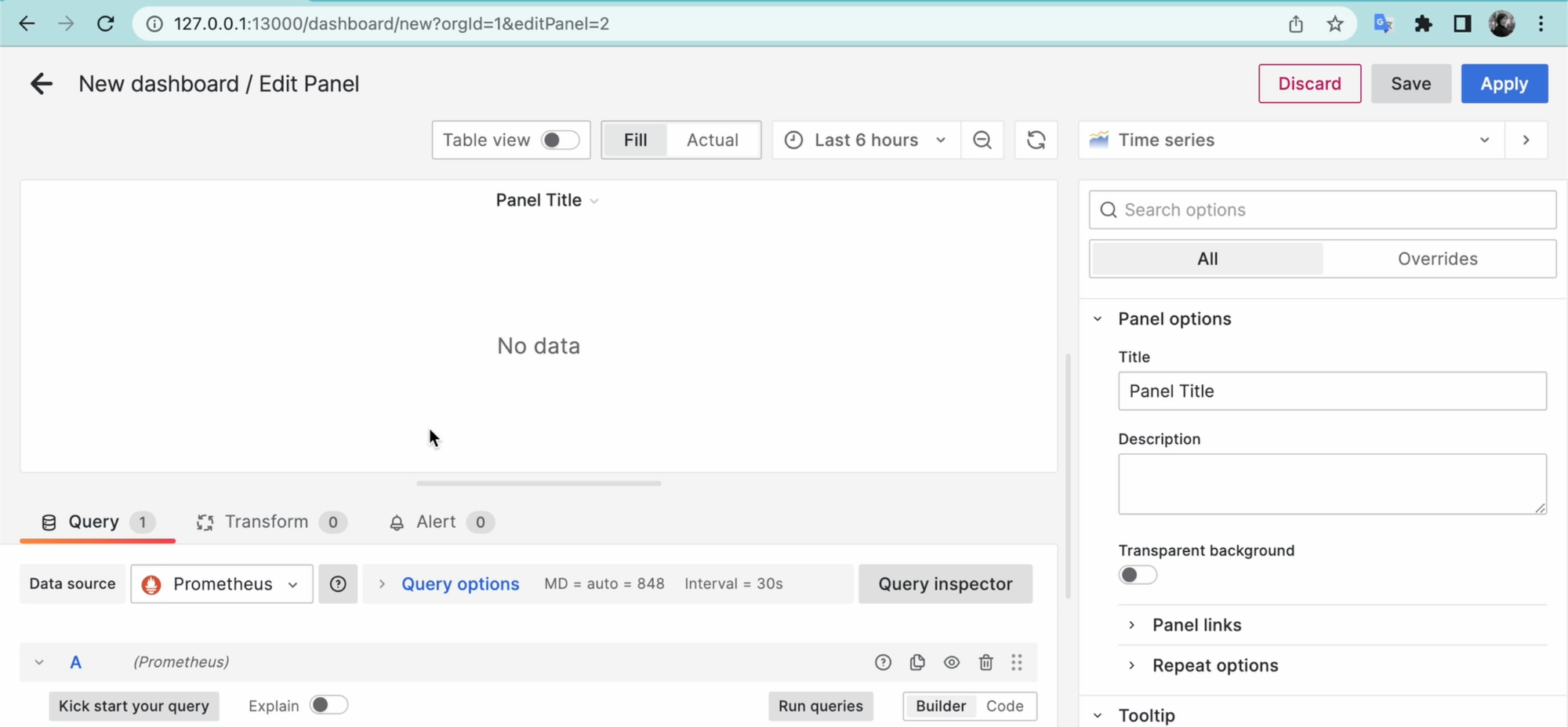
На этом дашборде нужно создать новую панельку, и перед вами покажется вот такой интерфейс:
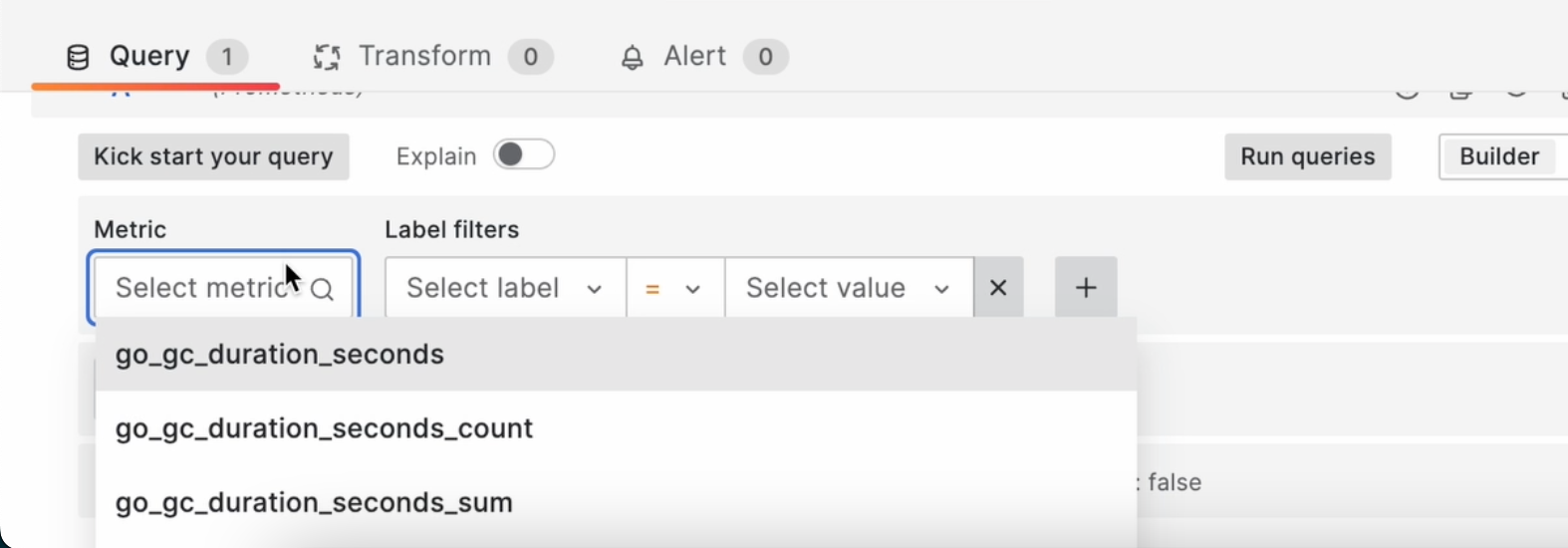
Кстати, графана замечательно справляется с промптами ваших метрик:
Но, прежде чем выводить новую панельку, давайте сделаем так, чтобы у нас в принципе появились какие-то данные. Для этого я запущу bombardier – это такое средство нагрузочного тестирования. Нужно запустить команду, которая будет делать запросы в 100 потоков на протяжении 30 секунд:
bombardier -c 100 -d 30s http://127.0.0.1:8081
Тем временем, я уже могу начать выводить эту метрику. Для того, чтобы вывести рейт какой-то метрики, нам нужна одноименная функция rate .
Передаем в неё нашу метрику, и в квадратных скобках интервал, за который будут усредняться значения. Получится что-то вроде:
rate(ads_http_request_count[1m])
Вуаля:
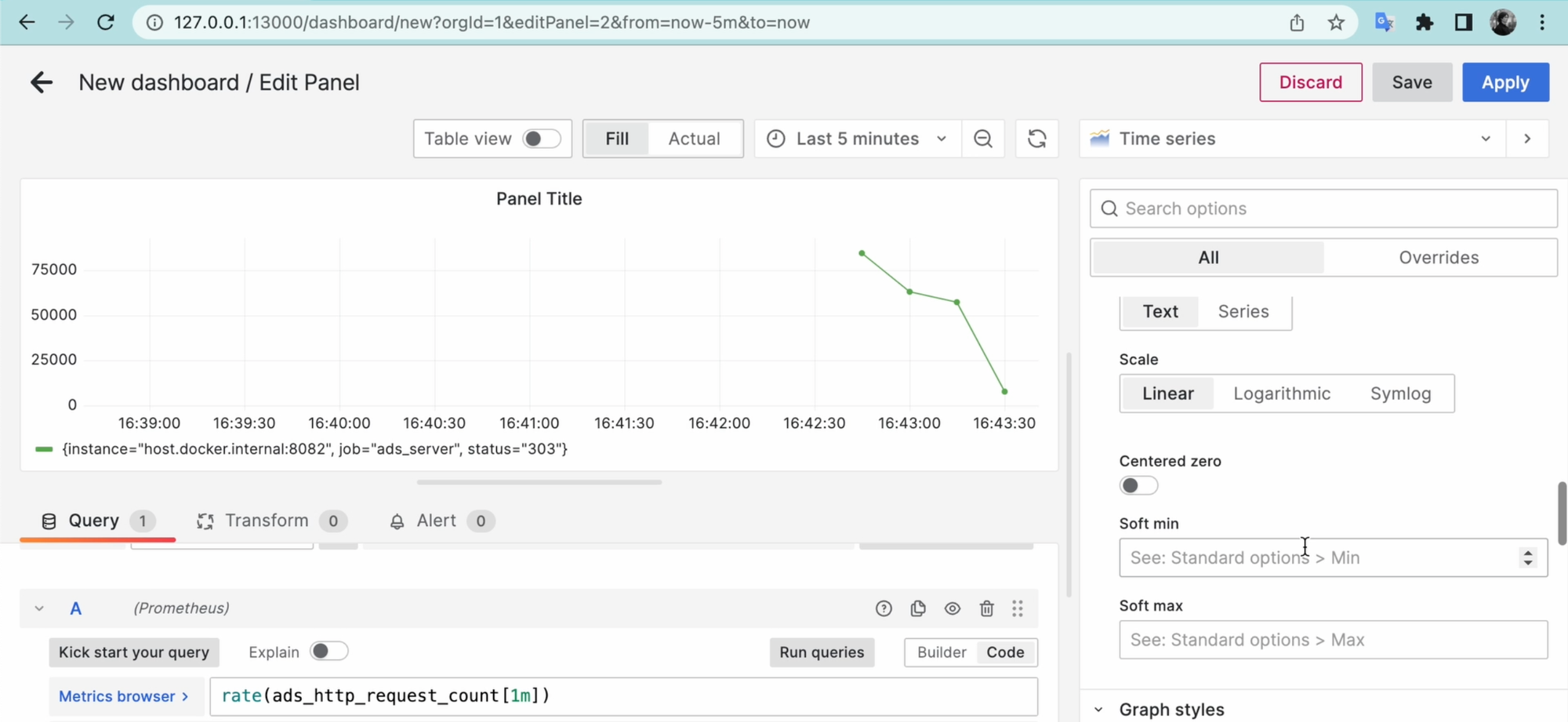
Вместо абсолютных показателей типа 30000-50000, вы можете явно указать единицу измерения. Среди этих единиц измерения есть такой формат как short. Выберем его, и теперь оно выводится в более удобном виде:
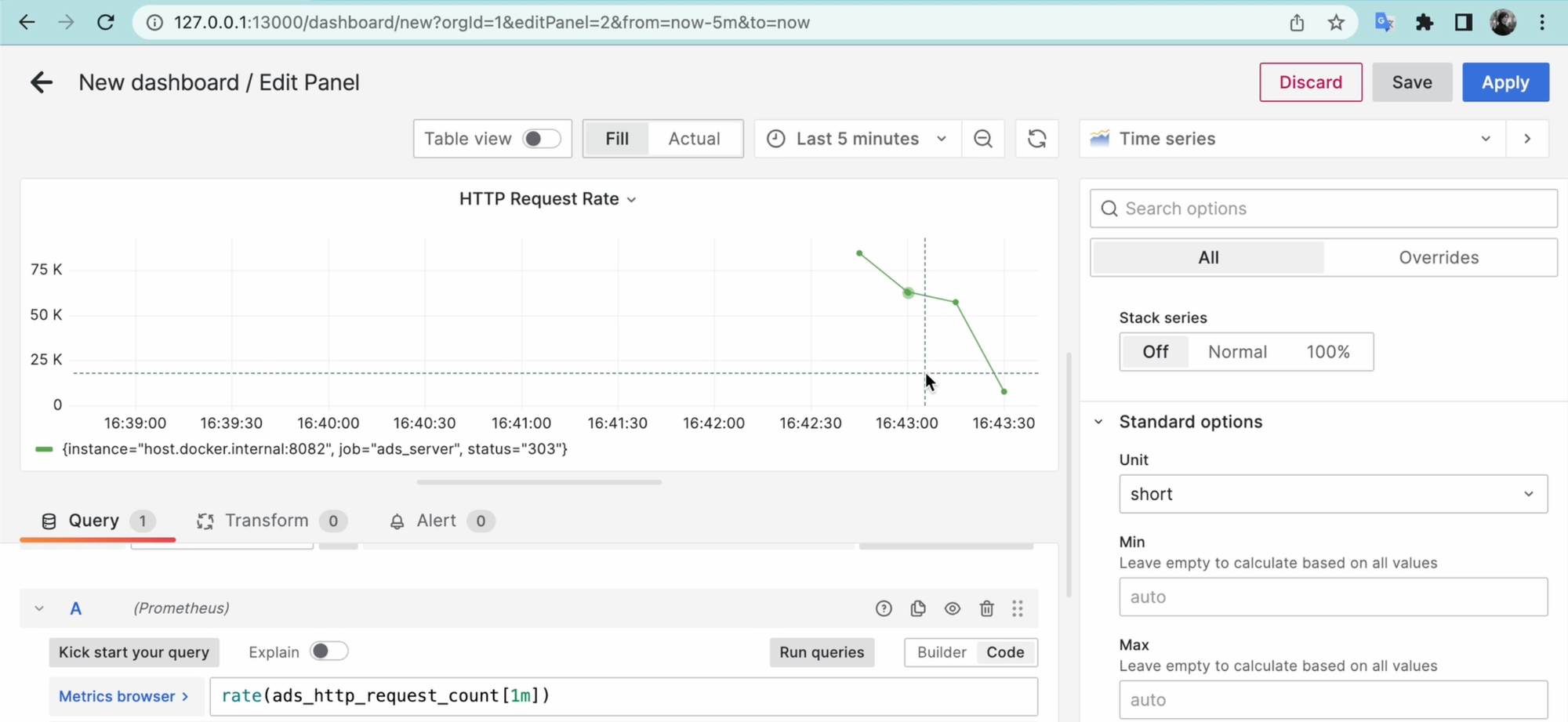
Обратите внимание на легенду, в которой выводится {instance="host.docker.internal:8082", job="ads_server", status="302"}.
Давайте вместо этого робовывода явно укажем, какие поля нам нужны. Например, я хочу видеть там только статус. Для этого в поле “Legend” нужно ввести шаблон, в нашем случае {{status}}. Результат будет такой:
Теперь давайте выведем длительность обработки запросов. Для этого создадим новую панель с таким PromQL запросом:
ads_http_request{quantile="0.9"}
Затем давайте выберем секунды в Standart Options -> Unit. Теперь мы увидим вот такой стройный график:
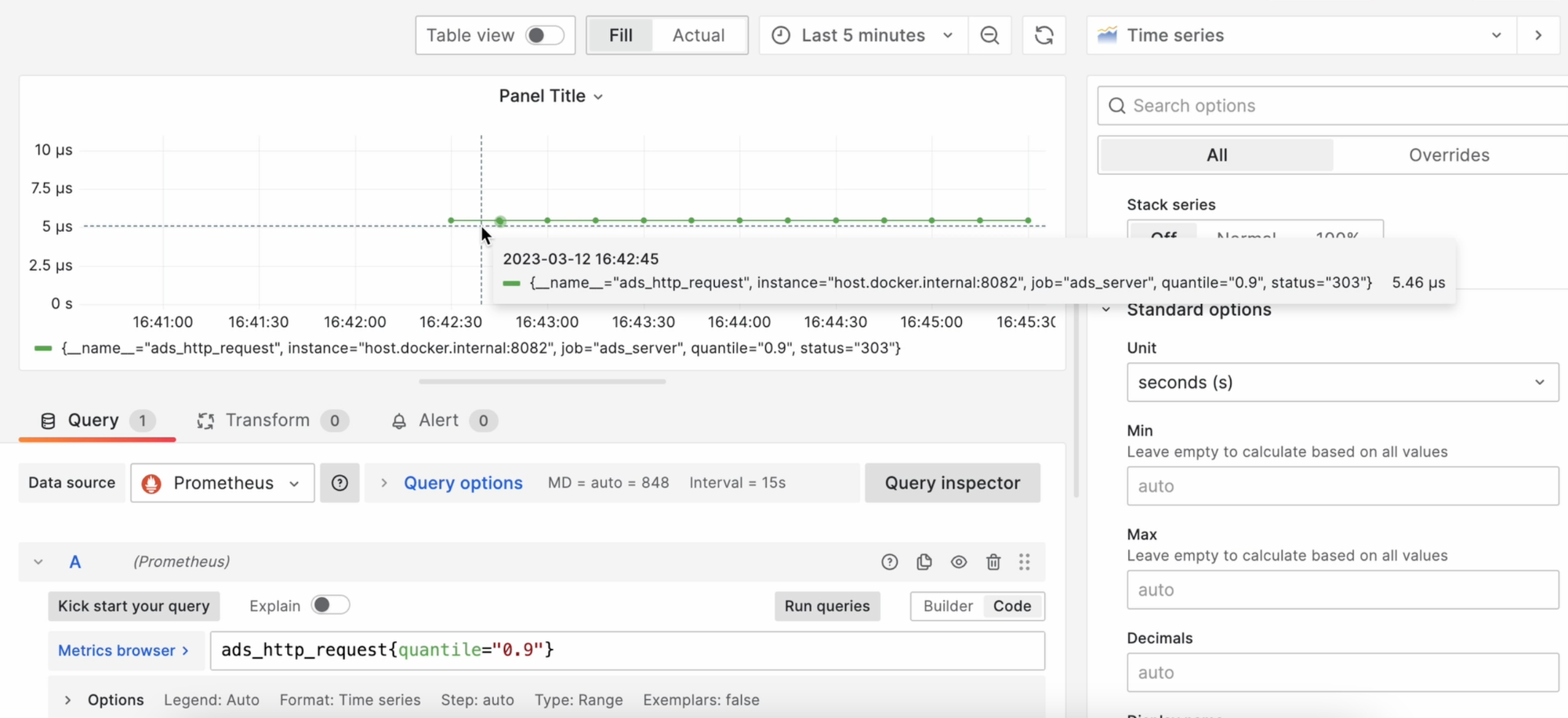
По которому становится понятно, что запрос обрабатывался смешные 5 мкс.
Stat
Итак, мы научились выводить графики, теперь давайте выведем rate в виде отдельного счётчика.
Просто скопируем запрос из первой панели rate(ads_http_request_count[1m]) в новую панель и выберем тип панели Stat.
Она выводит последнее значение (хотя можно это перенастроить, и вывести хоть первое, хоть среднее ). И, если я сейчас вновь запущу “бомбардировку” ротатора и обновлю панельку, то увижу график этих запросов. Правда, с небольшой задержкой, потому что Prometheus собирает данные раз в какое-то время:
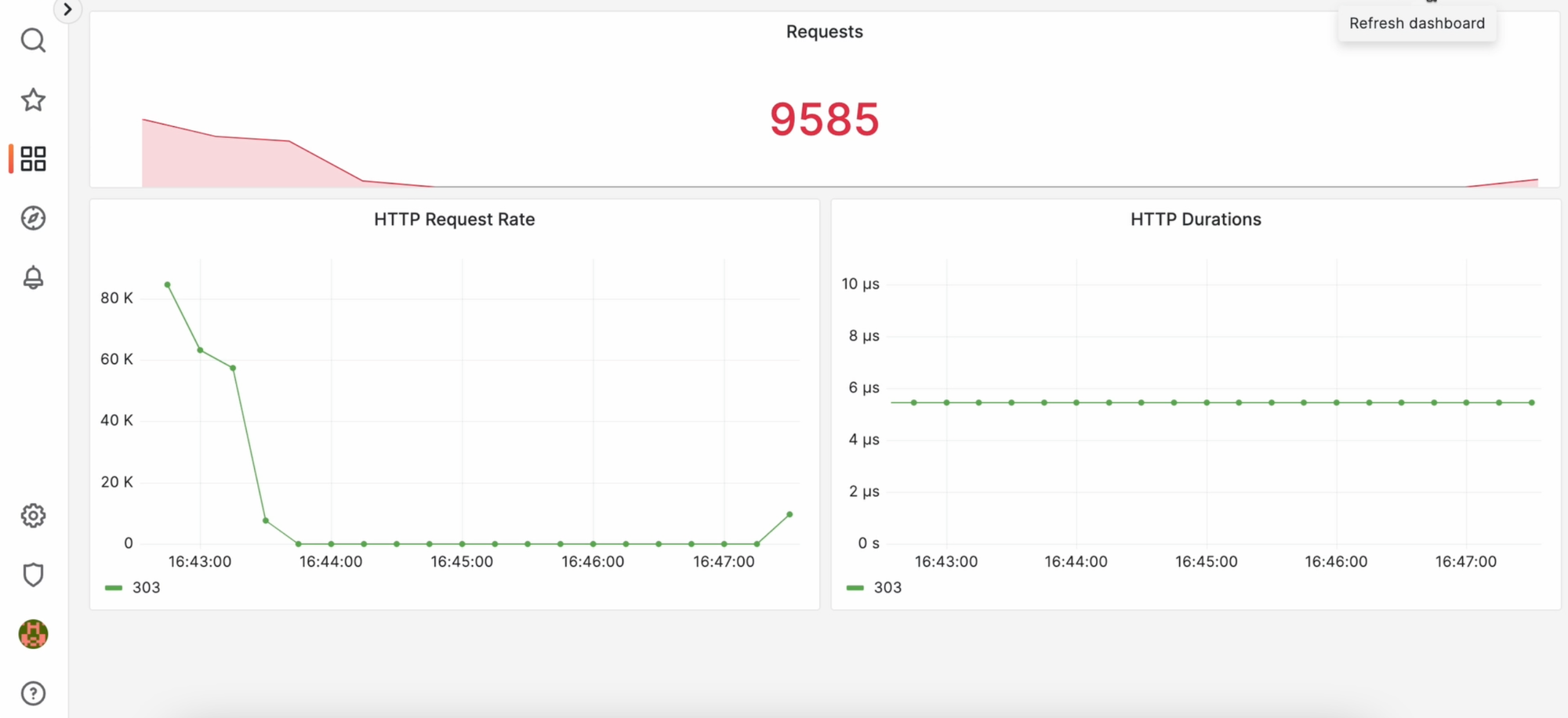
Но что будет, если я запущу второй ротатор?
Для этого поставим конфигурацию в IDE “возможность запускать несколько сущностей”.
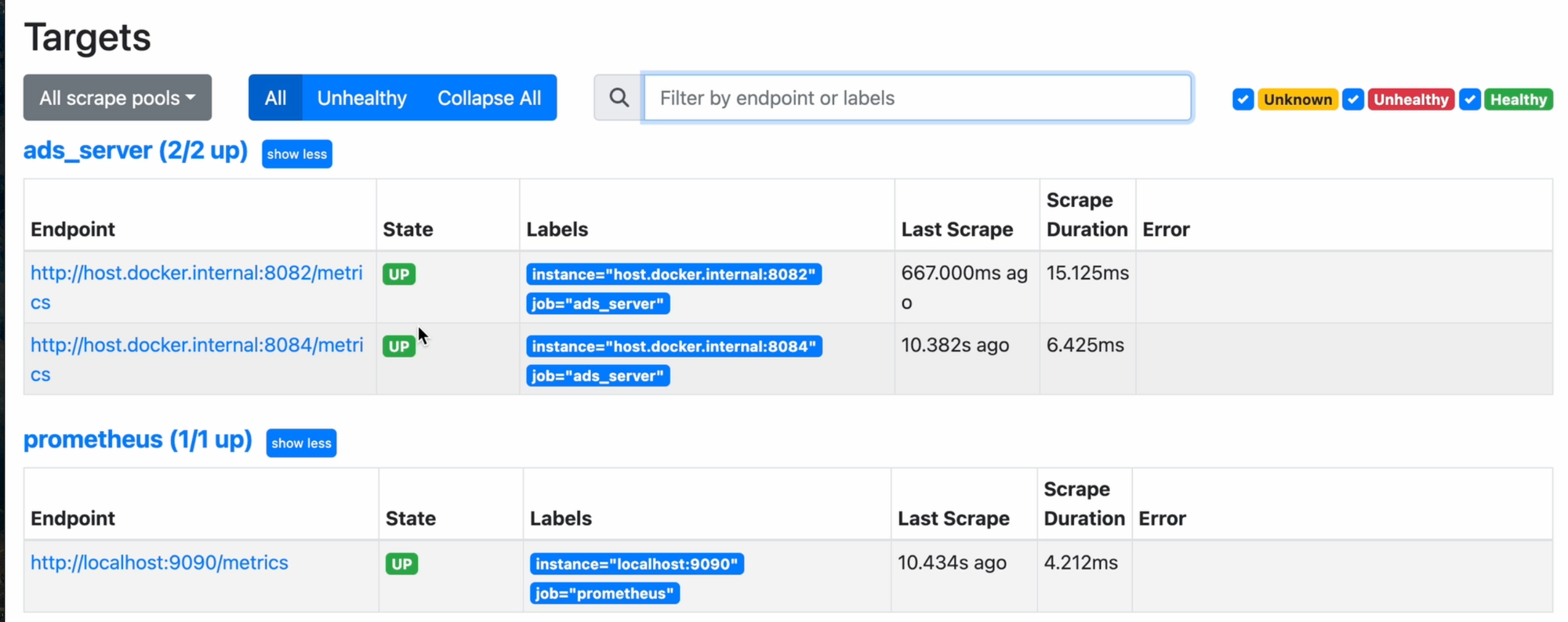
Запущу второй инстанс ротатора, для которого проставлю новую пару портов для 8083 и 8084. Перезапущу контейнер с прометеусом, и теперь у меня отображаются оба инстанса в Targets:
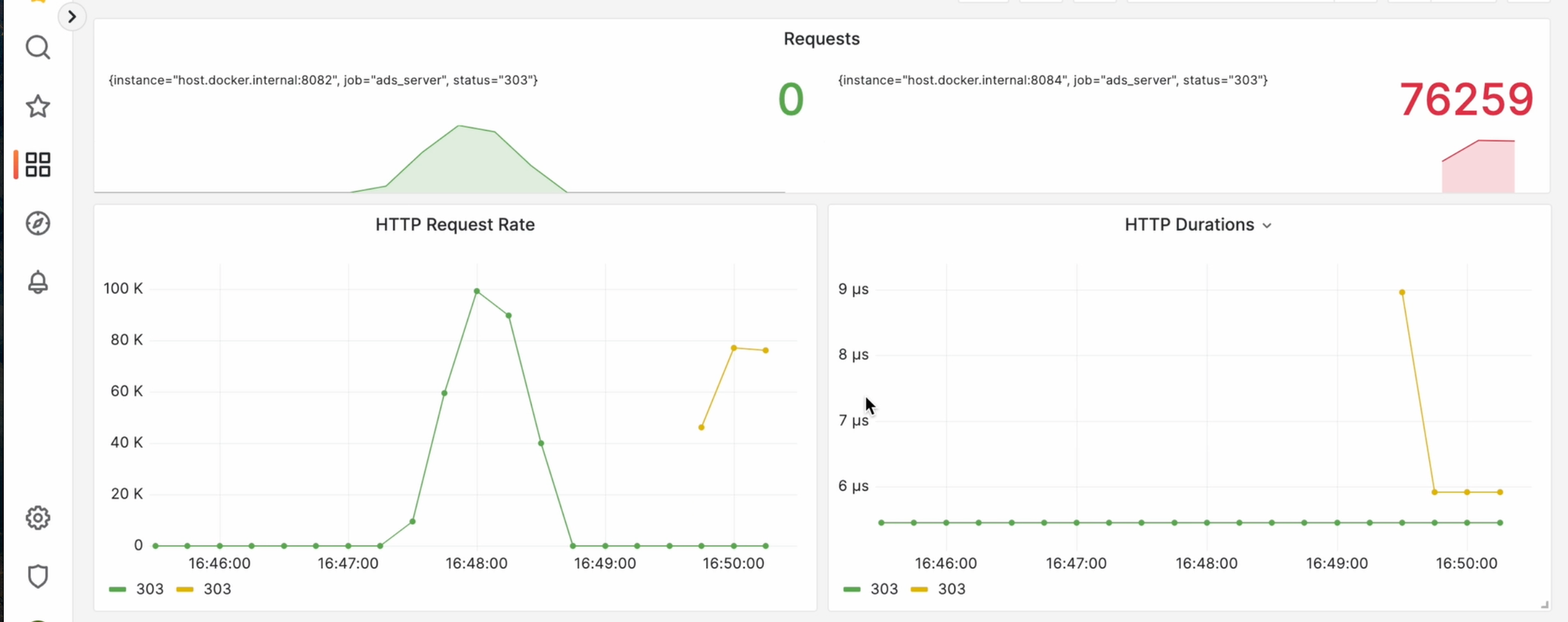
А что будет, если я сейчас запущу бомбардир на второй ротатор? Запускаю, возвращаюсь к дашборду, и кажется у меня задублировались данные..
Переменные
Что мне делать, если я хочу отобразить только одну кривую для какого-то конкретного инстанса? Нужно использовать переменные. Переменные устанавливаются на уровне дашборда.
Открываем настройки дашборда, и слева видим секцию Variables:
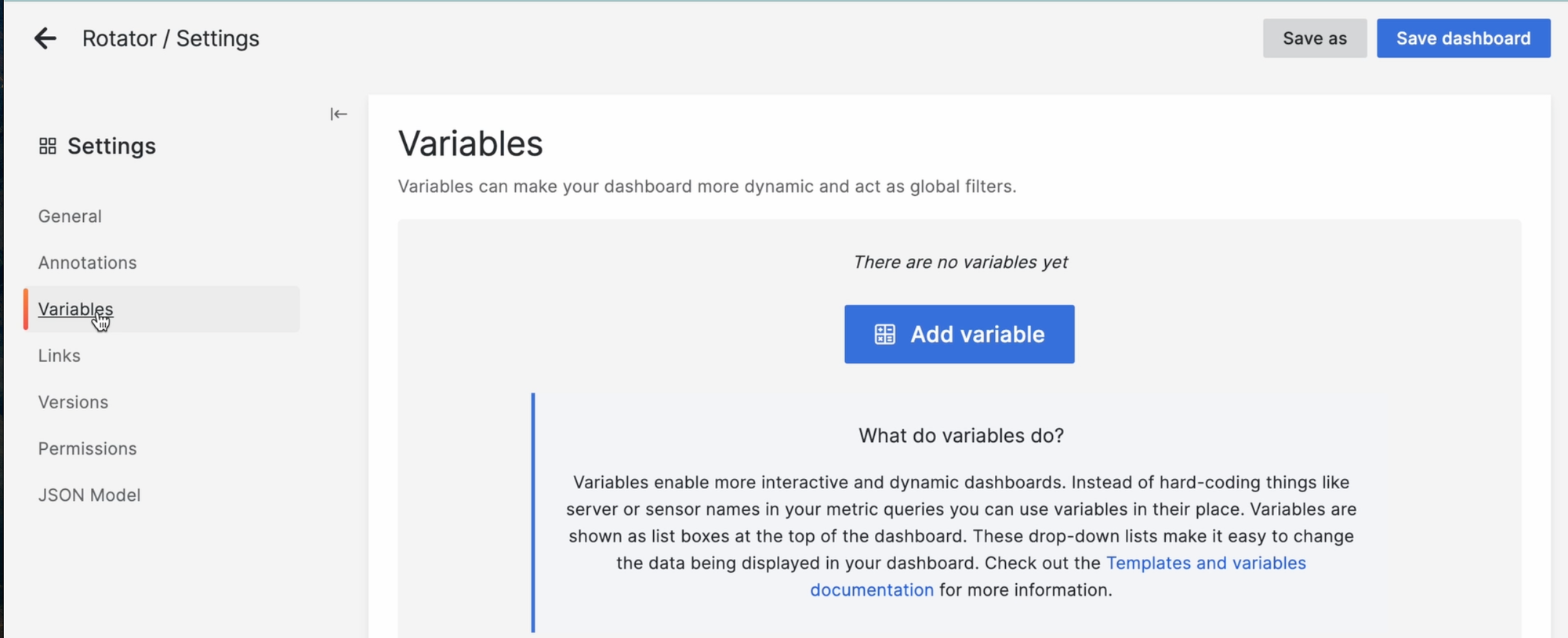
Кликаем “Add variable” и задаём некое имя, которое будет доступно во всех метриках:
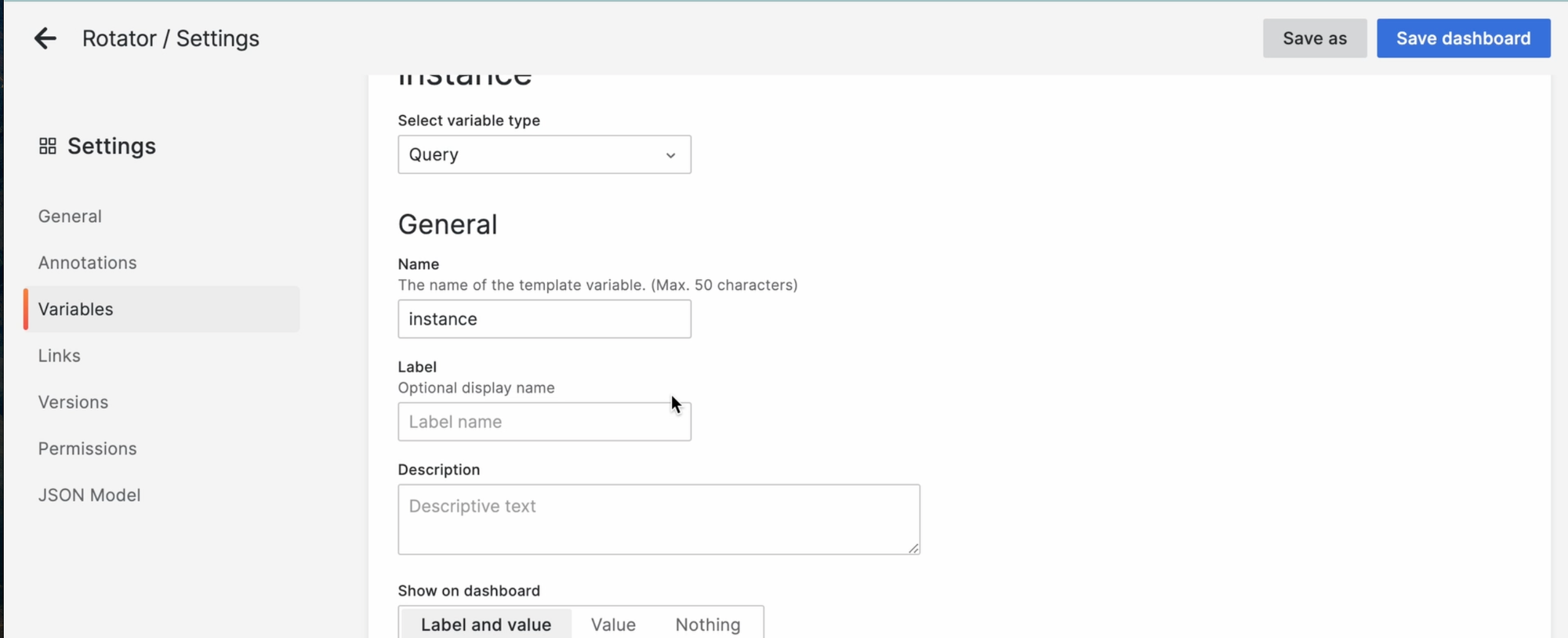
Теперь нам нужно ввести запрос, который вернёт значения для выпадающего списка.
В шаблонизаторе Grafana есть очень классная функция, которая называется label_values.
Она возвращает все возможные легенды какой-то метрики.
В моём случае, я возьму за основу метрику ads_http_request и получу все instance:
label_values(ads_http_request, instance)
Графана сразу их показала в превью:

Сохраняю, и теперь, после того, как я создал эту переменную, она у меня отобразилась сверху, и я могу её использовать в запросах.
Давайте вновь откроем панельки, и используем прямо в запросе новую переменную:
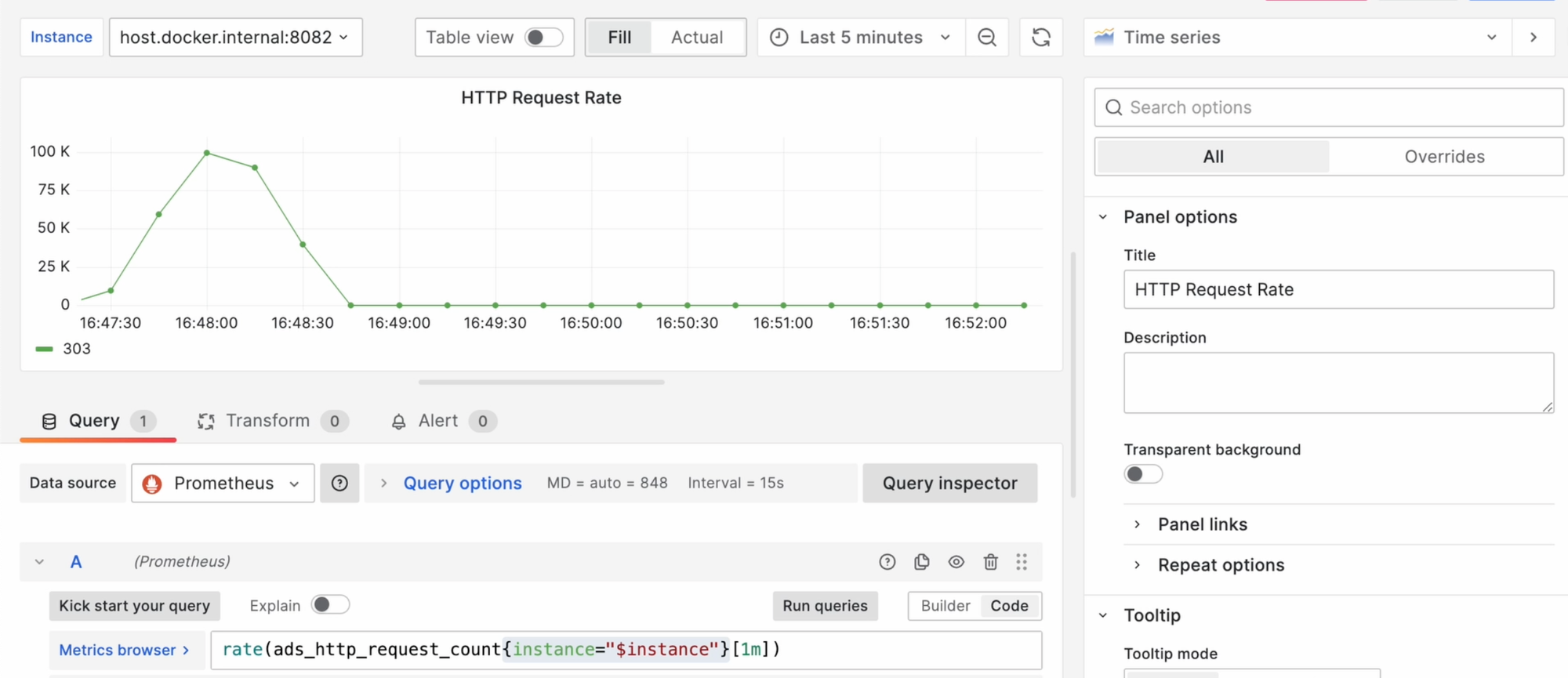
Как видите, синтаксис PromQL остаётся тем же, просто в фильтре можно указать $instance.
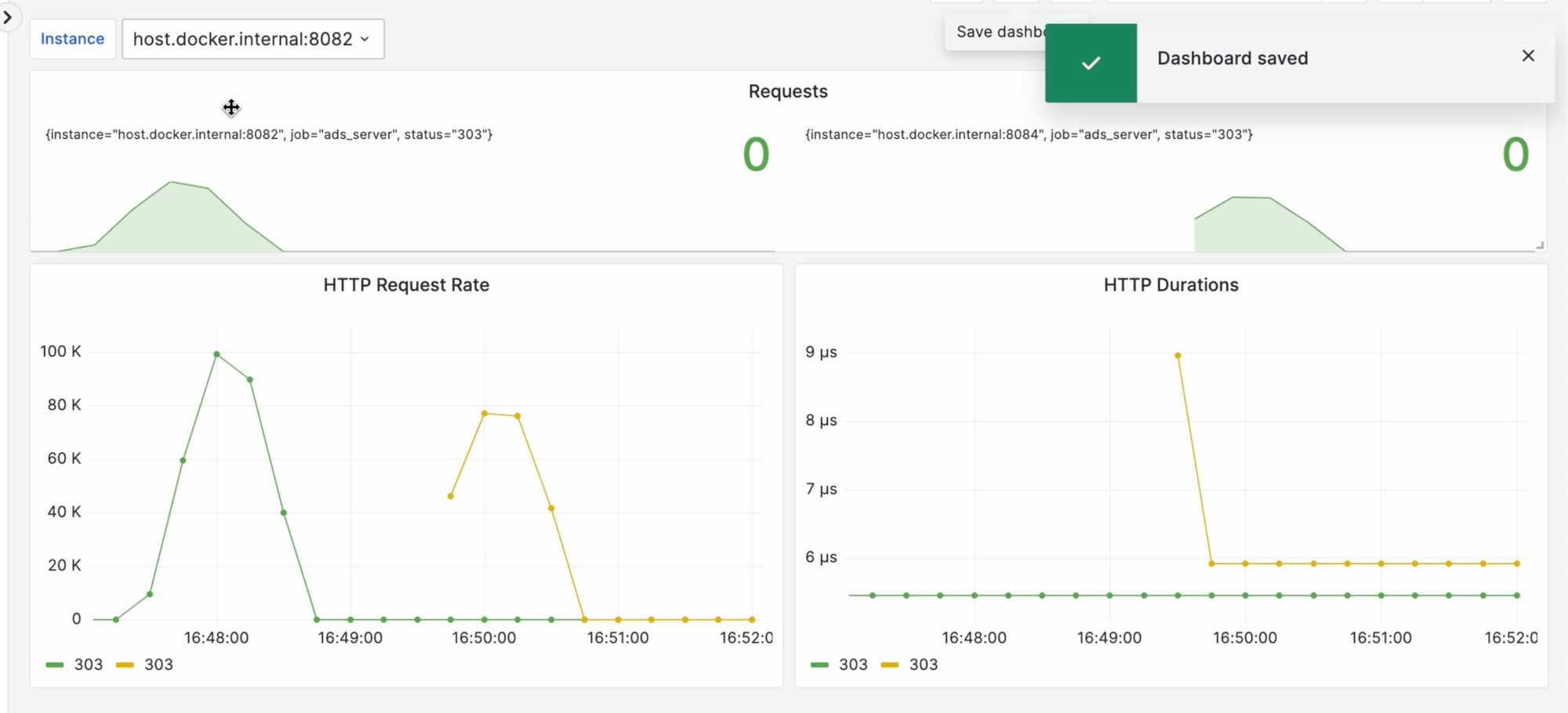
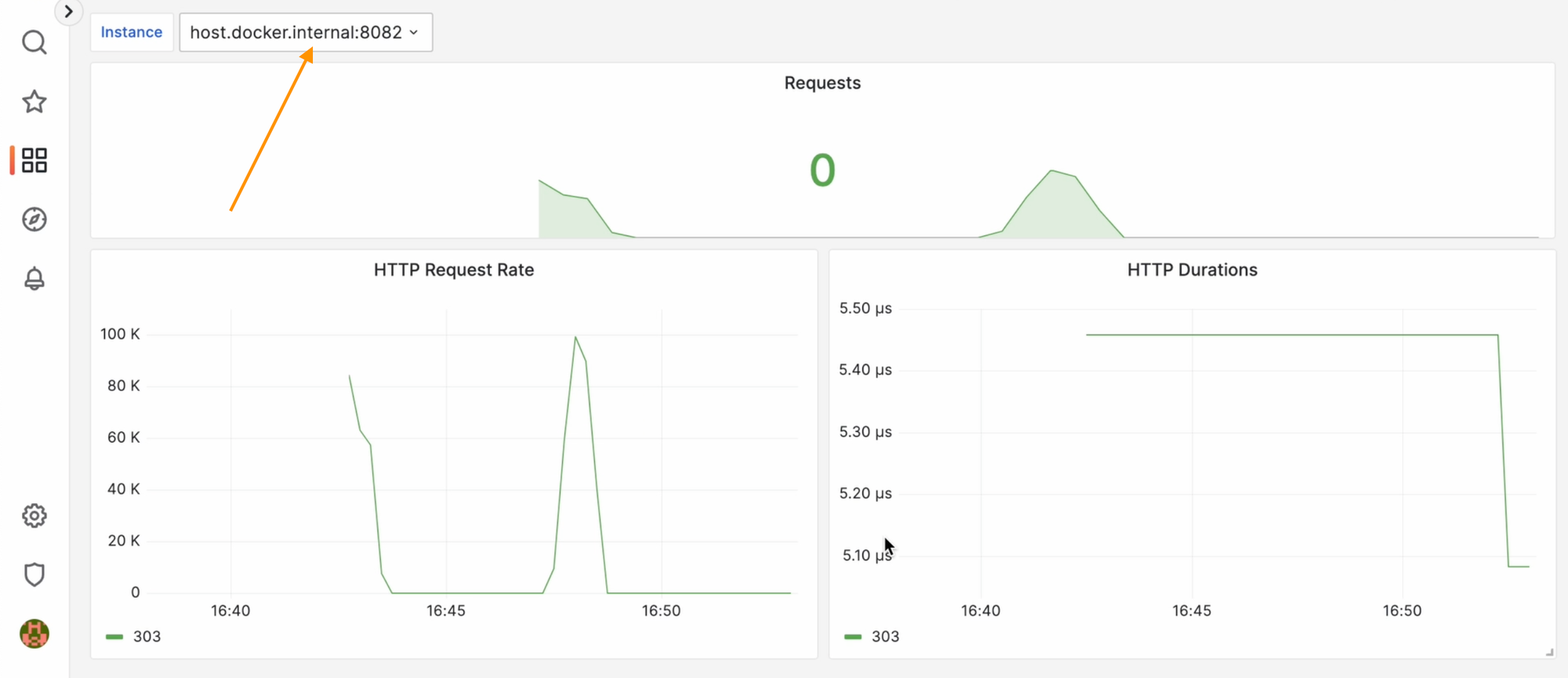
Добавим эту магию во все панели, которые создали ранее. Теперь мы буквально одним выпадающий списком можем менять instance ротатора, метрики которого меня интересуют в данный момент.
И на одном дашборде можно переключать метрики разных ротаторов:
Аннотации
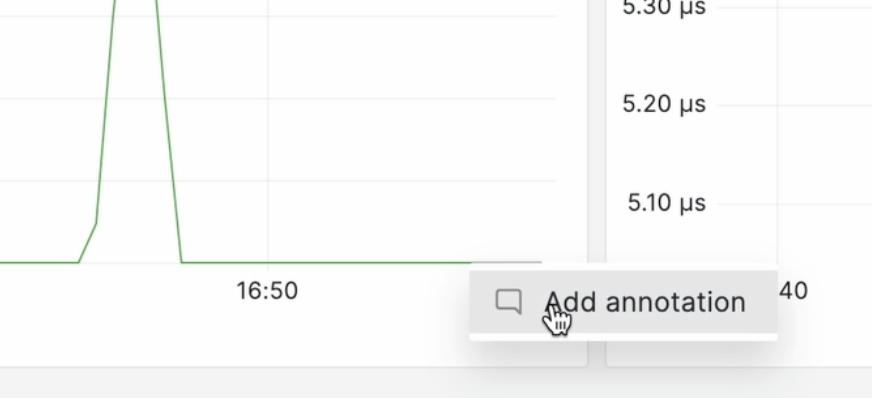
Допустим, вы загрузили какое-то обновление или начали процесс нагрузочного тестирования и вы знаете, что начали делать это в 16:53. Знать вам это время нужно для того, чтобы понять, в какой момент у вас может поменяться график в связи с обновлением.
Запоминать самому это не очень удобно, и, к счастью, графана предлагает в этом случае создать аннотацию. Достаточно кликнуть прямо по графику, нажать Add annotation, написать комментарий врде “Здесь запущен бомбардир”, и к выбранному времени добавится аннотация!
После сохранения у вас на графике будет отображаться вертикальная линия, при наведении на которую вы увидите свой комментарий:
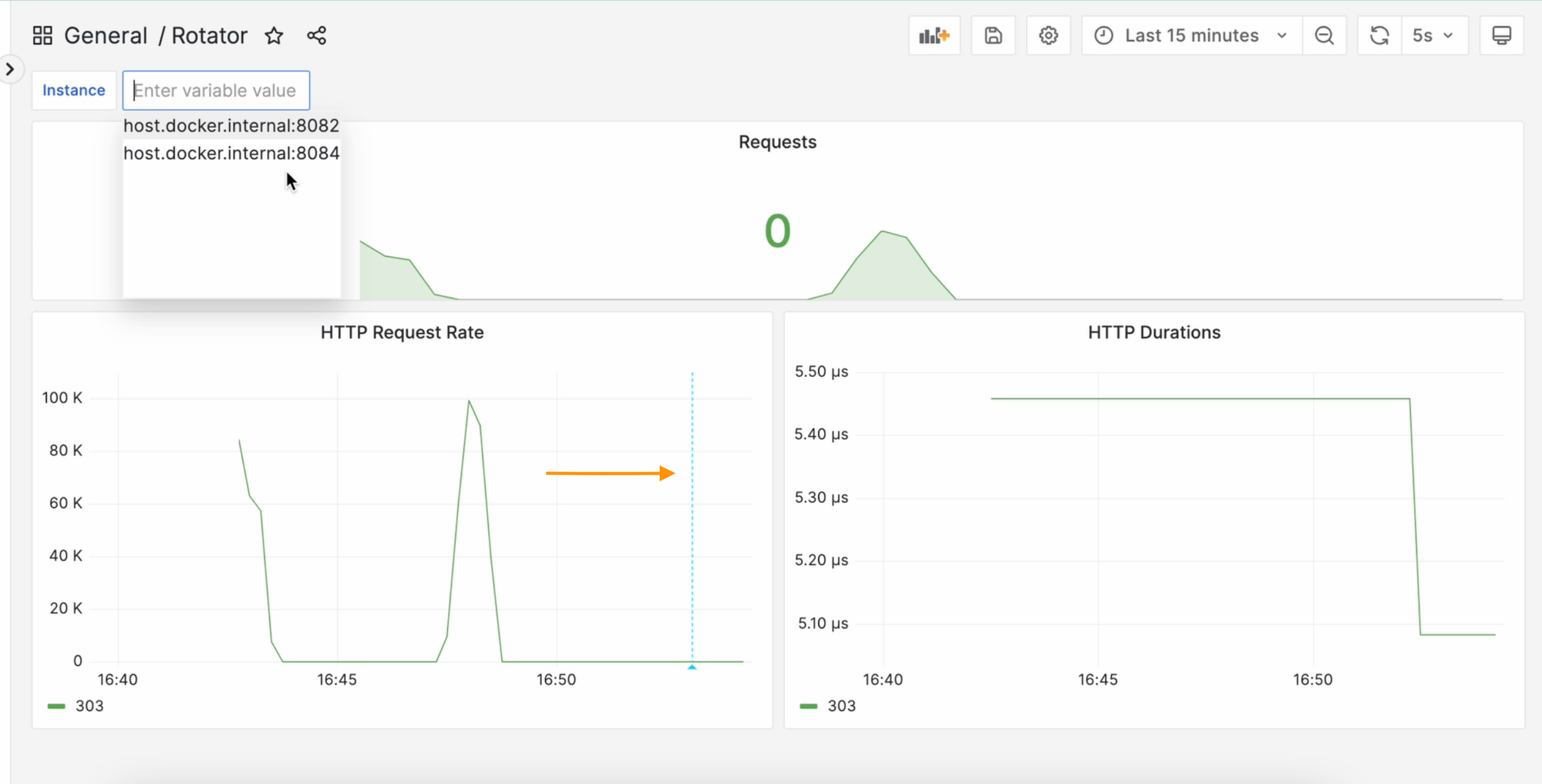
Отличный способ показать, что после какого-либо действия что-то должно измениться, когда вы, например, загрузили обновление.
Подключение ClickHouse
В процессе заигрываний с графаной мы навставляли кучу статистики в кликхаус. А можно ли её вывести на том же дашборде? Конечно можно!
Для начала, аналогично прометеусу подключим и кликхаус. Правда, для него понадобится поставить плагин, но тоже буквально в пару кликов. Перейдём в Settings -> Plugins и найдём там “Clickhouse”:
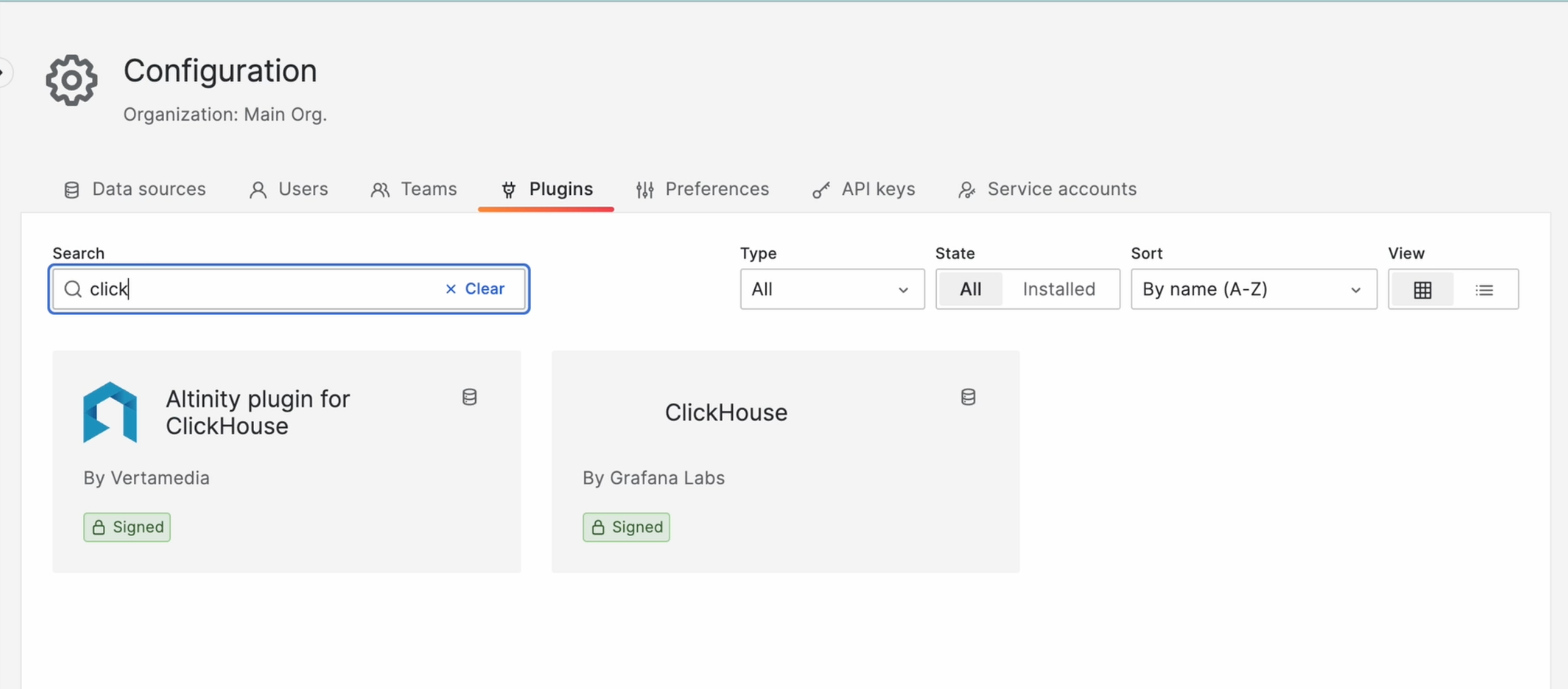
Устанавливаем плагин, и с этого момента вы можете создавать источник из Clickhouse.
У меня контейнер называется clickhouse-db, соответственно это и будет в поле Name:
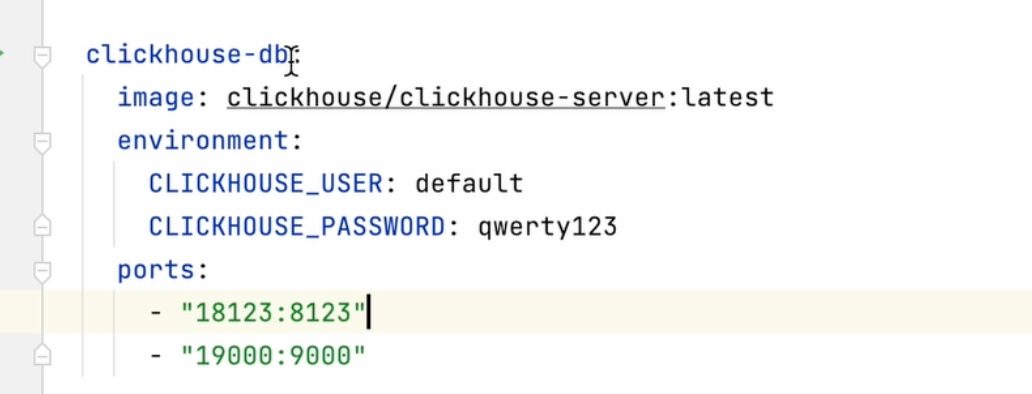
Порт стандартный 9000, потому что мы внутри докер сети. Username - default, пароль - qwerty123. Сохраняем, тестируем, проверяем, что источник работает.
Теперь нужно составить запрос. Возвращаемся к дашборду, и создаём новую панель с источником Clickhouse. Grafana даже предложит поюзать удобный билдер запросов, чтобы вы не писали его руками:
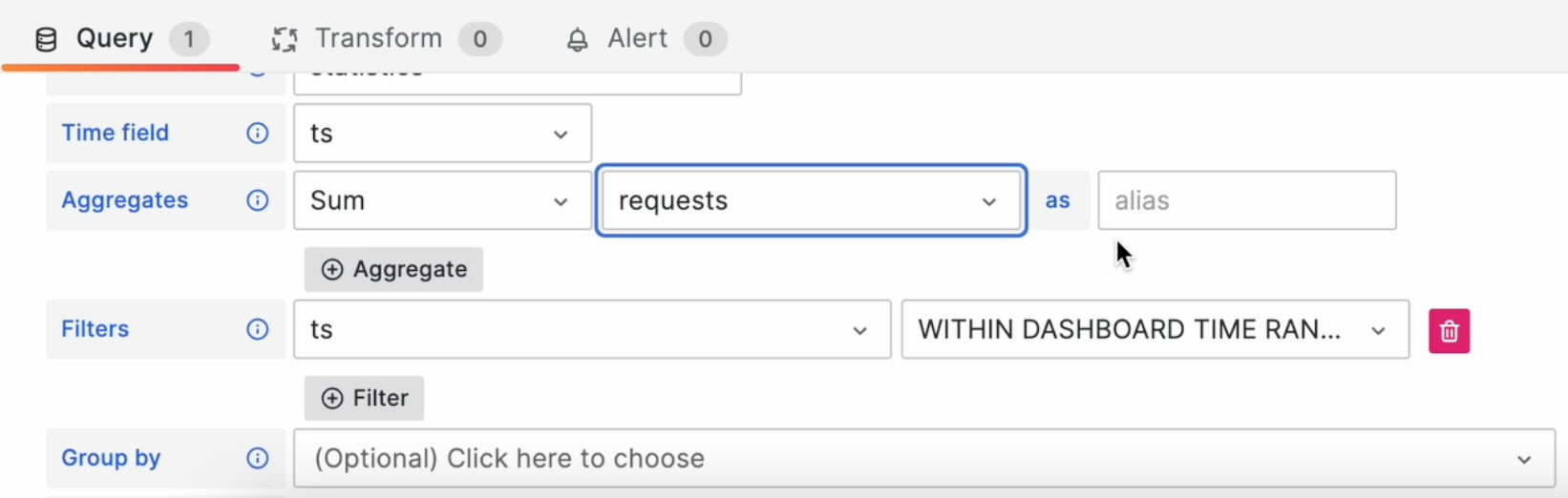
Выбираем базу данных, таблицу, выбираем сумму запросов:
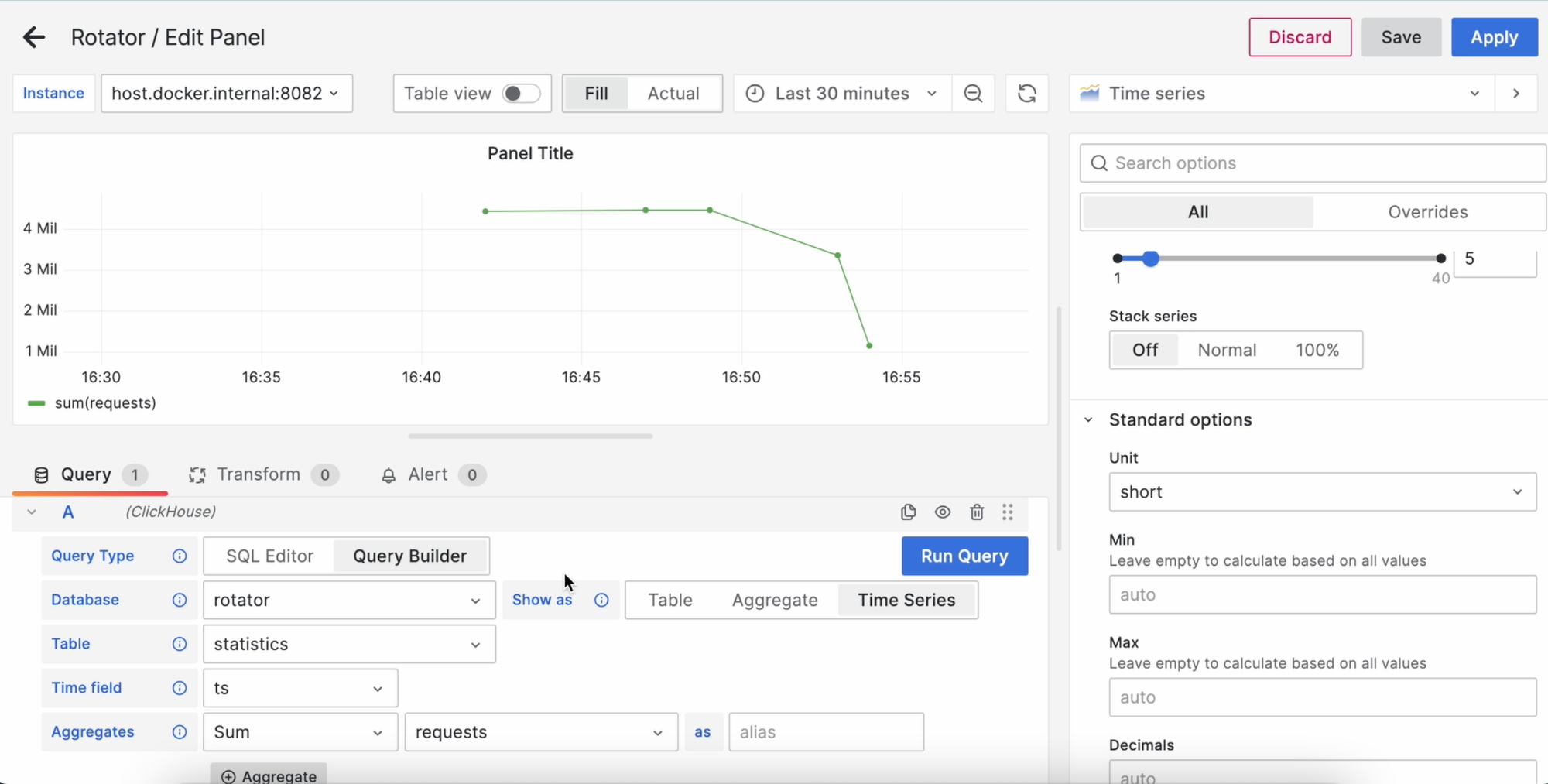
Запускаем и видим наши запросы:
Но что, если мне нужно видеть ещё и браузер? Тогда я выбираю текстовой редактор SQL Editor и вручную добавляю браузер:
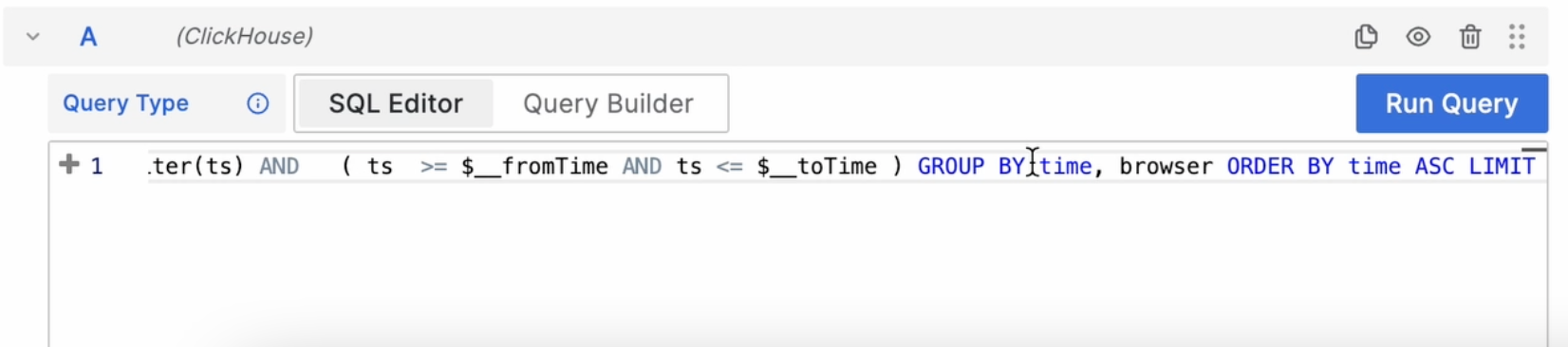
Алертинг
Большая и важная фича Графаны – алерты. Благодаря алертам вы можете настроить автоматические уведомления, если что-то случается с вашими сервисами.
Настройка телеграма
Давайте настроим алерты в телеграм канал, если вдруг упадёт один из инстансов ротатора.
Для этого нам понадобится три вещи:
- Канал в Telegram, куда будут отправляться алерты
- Бот, который их будет отправлять
- ID канала
Создание бота
Начнём с создания бота у BotFather . Наверняка вы уже видели эту процедуру, которая на выходе нам даст токен для бота.
Создание канала
Далее создадим канал, в который будут приходить алерты. В него нужно пригласить бота.
Получение ID канала
Как же нам теперь получить айди канала? Есть много разных способов, но самым безопасным я нахожу следующий:
- Пишем в чате что-то в духе
/test @mybot(то есть меншеним нашего бота и запускаем несуществующую команду) - Берём токен для бота из BotFather
- Подставляем токен в специальный адрес для получения апдейтов:
https://api.telegram.org/botТУТВАШТОКЕН/getUpdates
Открываем полученное в браузере и стягиваем ID чата:

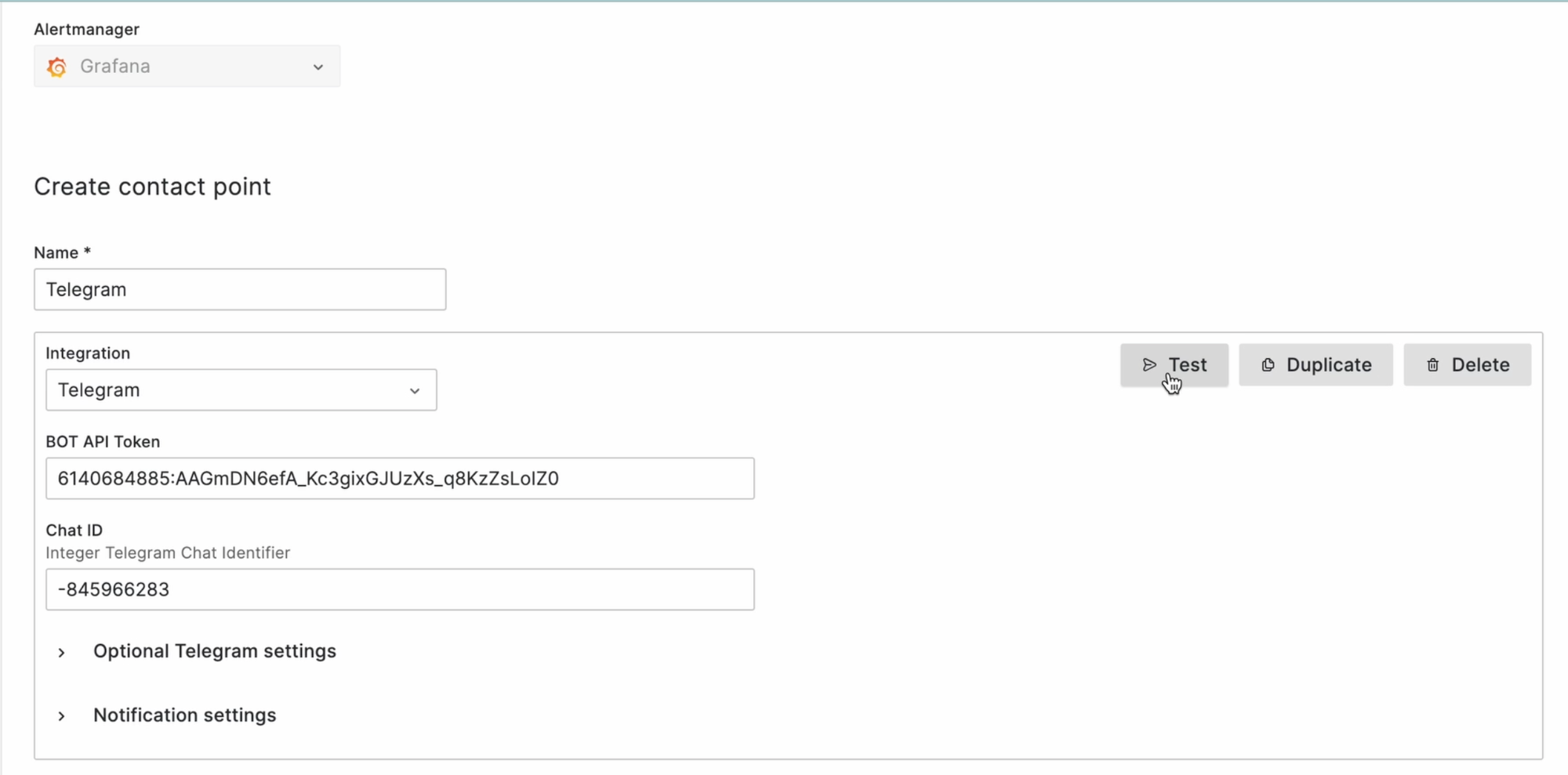
Теперь токен и ID чата мы можем перенести в графану, создав для этого канал нотификаций. Для этого переходим в раздел Alerting на вкладку Contact Points, создаём, и заполняем ID и токен, которые мы получили ранее:
Тестируем интеграцию и отправляем нотификацию:
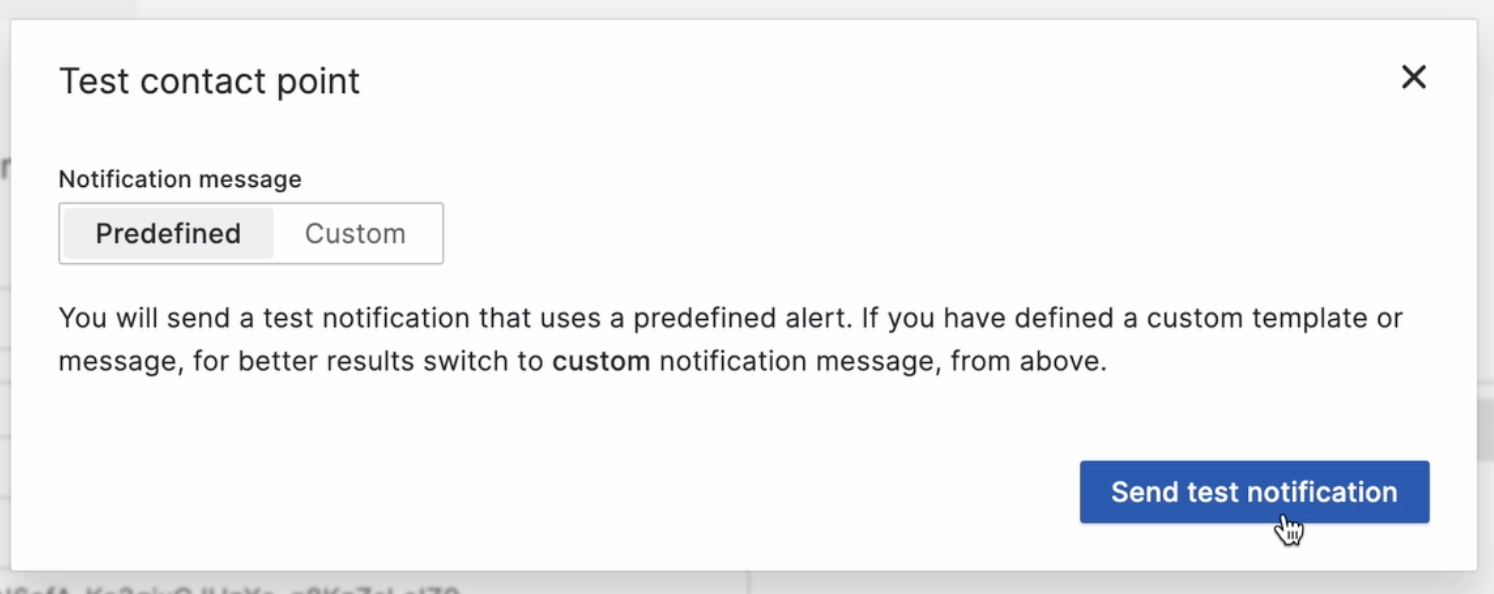
Вуаля, Бот подключён! Он нам уже отправил нашу нотификацию такого вида:

Настройка алерта в графане
Теперь возвращаемся к нашему дашборду. Нам нужно добавить панель, в которой мы выведем график живости инстансов ротатора. За статус таргета в прометеусе отвечает метрика up. Эта метрика выводит единичку, если сервис живой, и нолик, если нет:
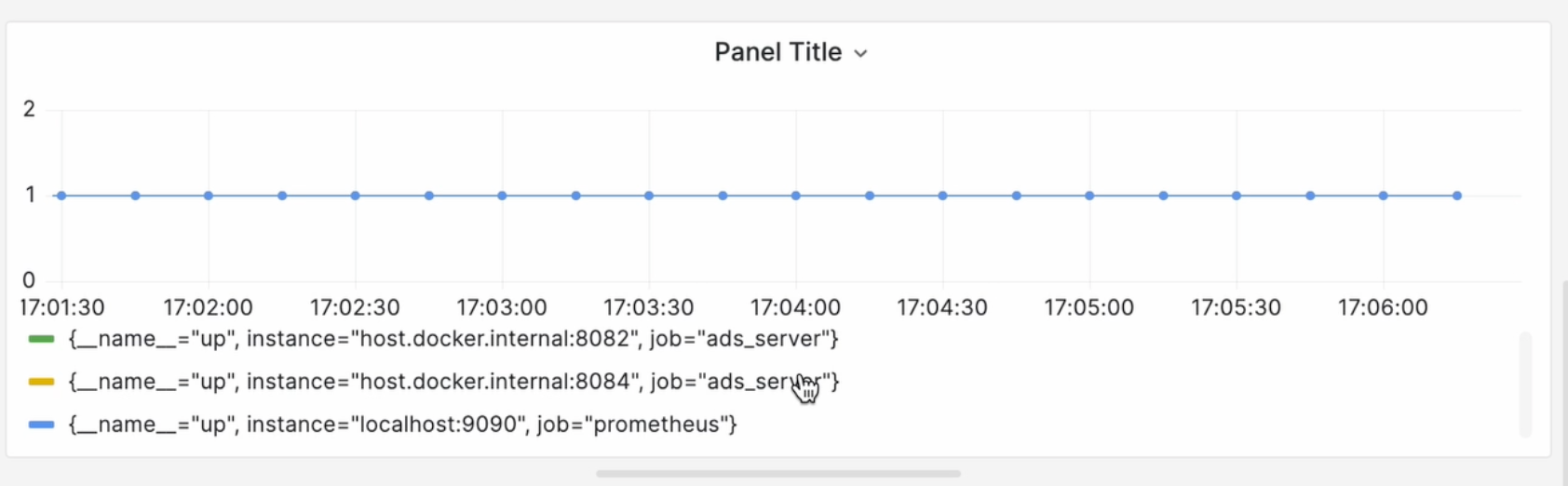
В ней же есть фильтр по джобам. А поскольку нас интересует только ротатор, я ввожу up{job="ads_server"} и вижу, что оба инстанса живые:
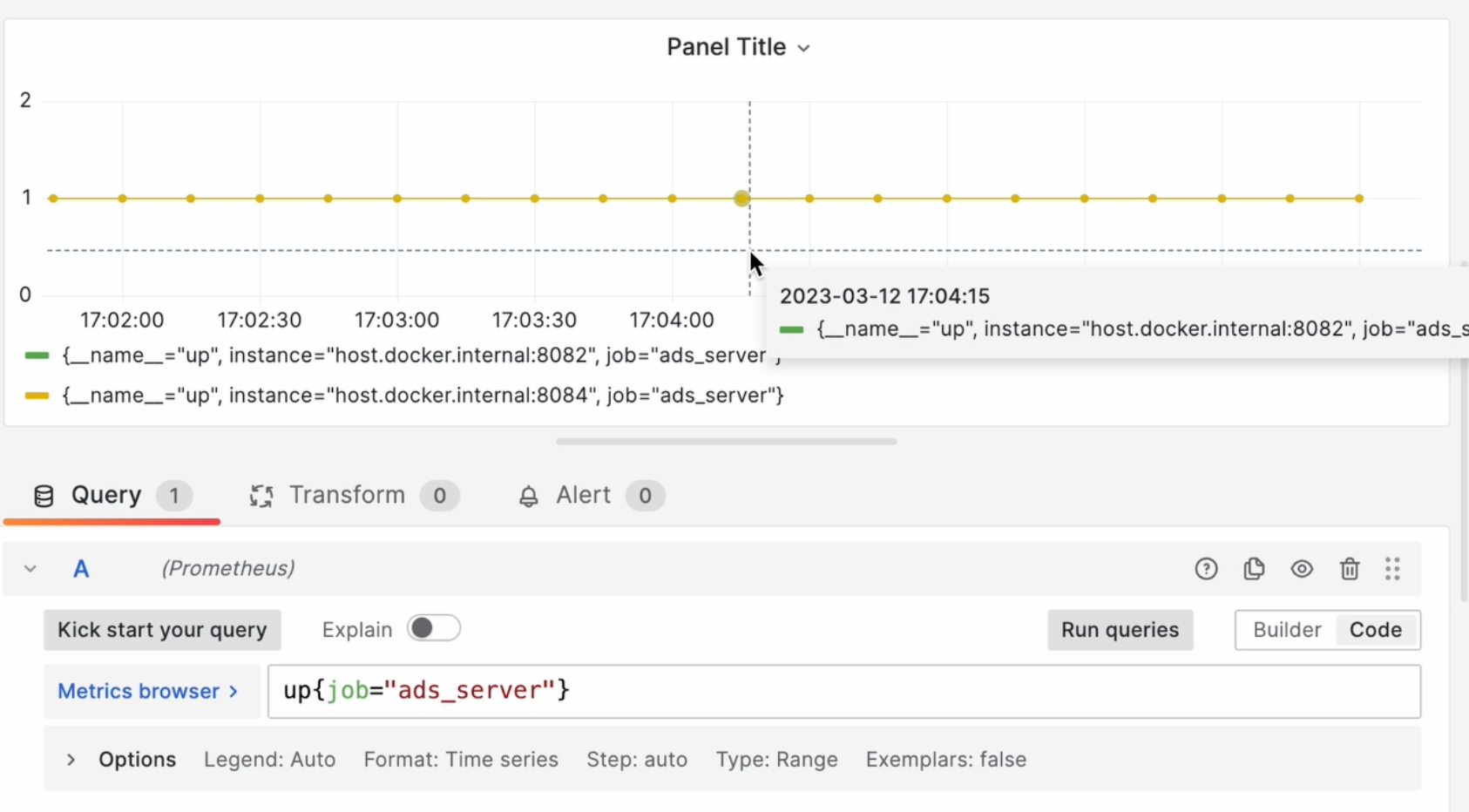
Сохраняем панель, открываем её редактирование вновь и добавляем Alert, и теперь перед нами показывается очень удобный графический интерфейс:
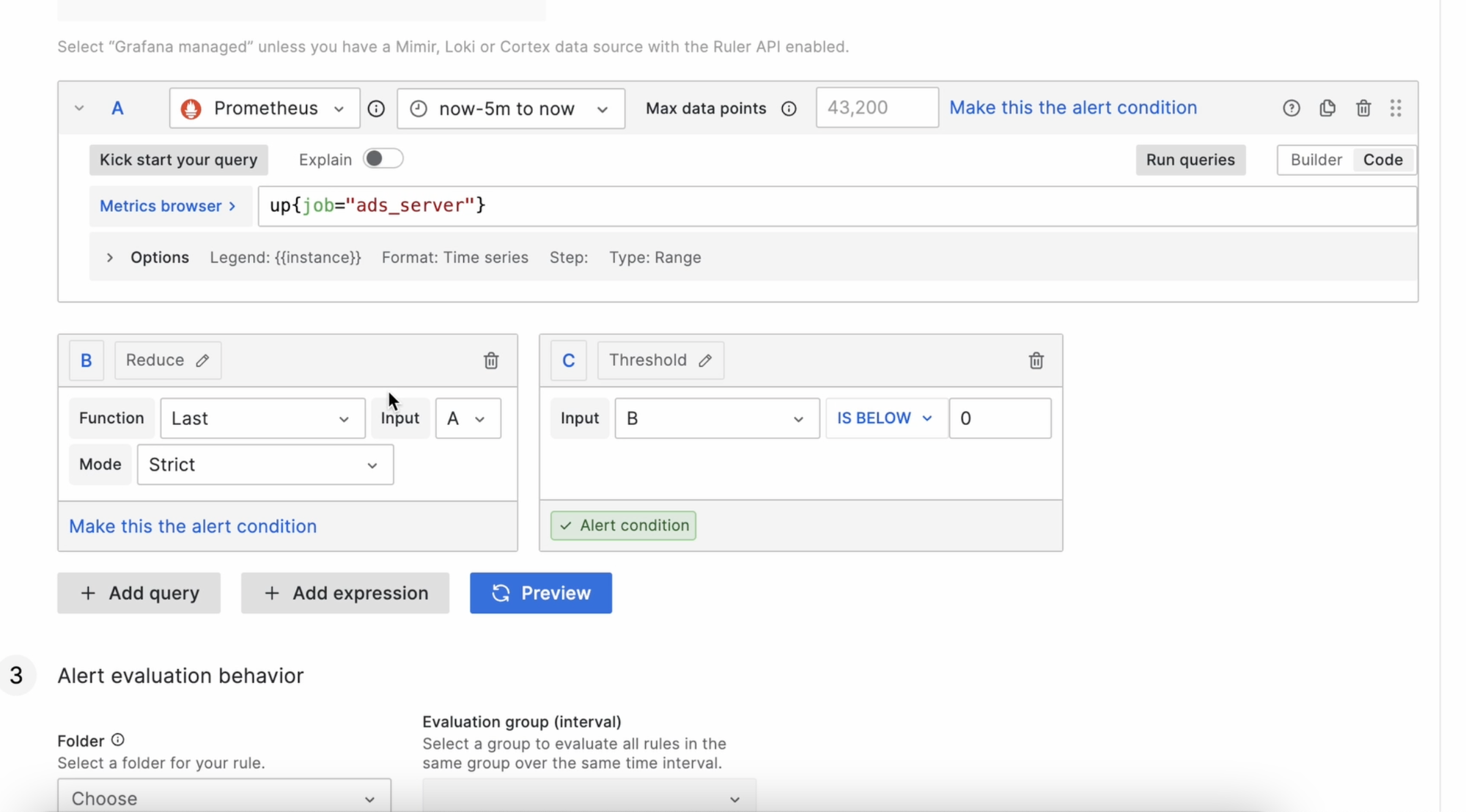
Поставим условие, что нам нужны алерты, когда значение опускается ниже 1:
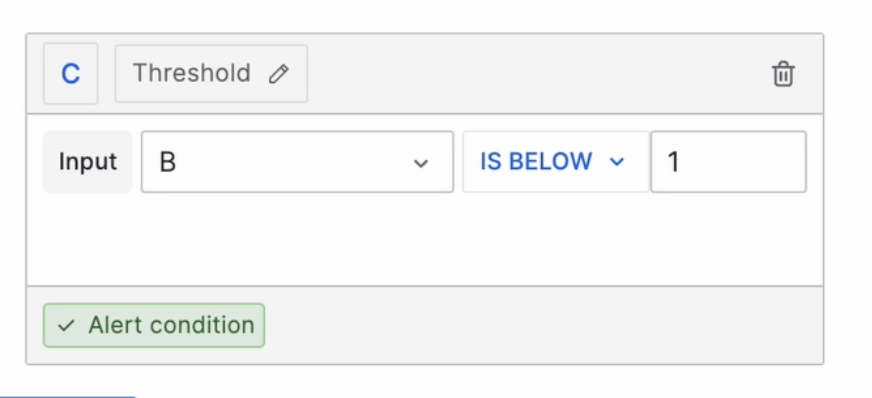
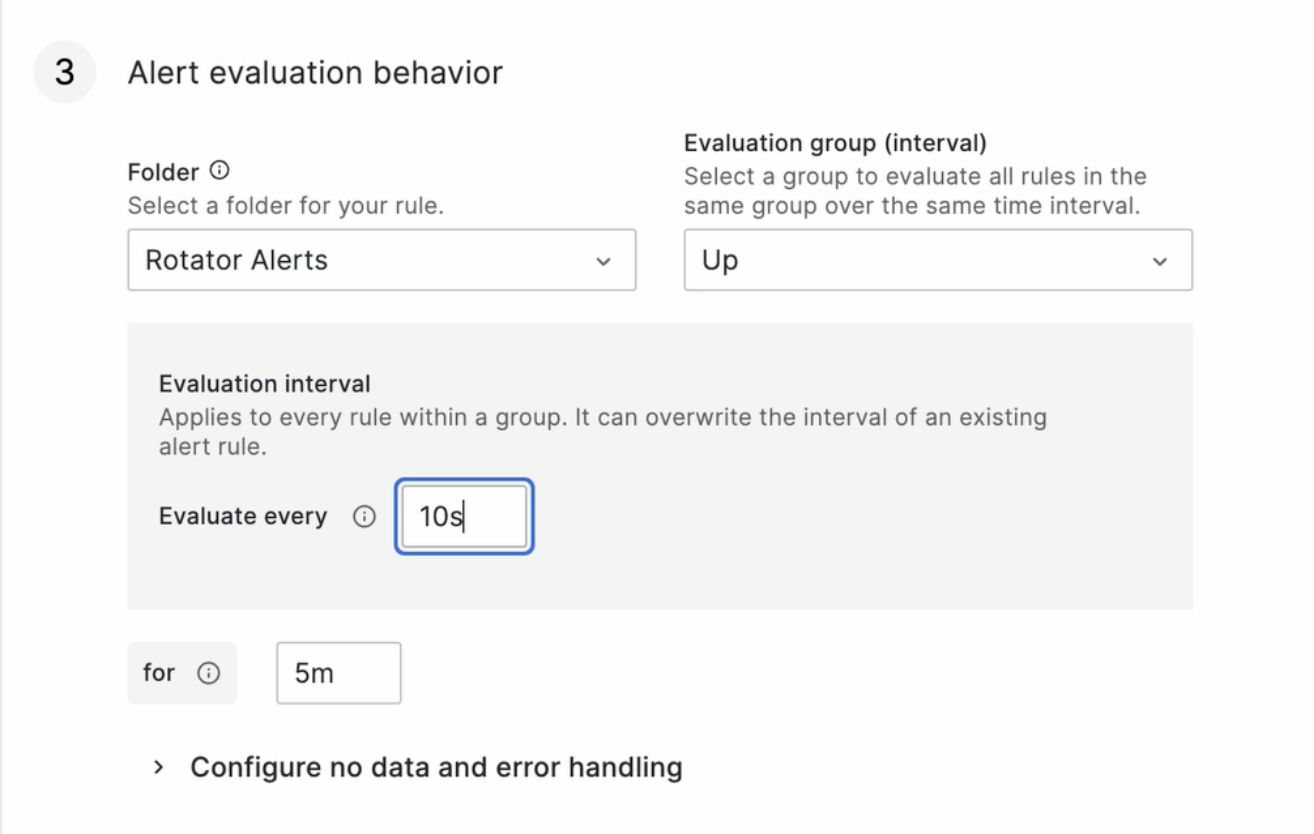
Далее установим проверку раз в 10 секунд, чтобы быстрее получить результат:
У алерта есть три состояния:
OK– всё хорошо (ok)Alerting– что-то случилось, тогда он будет отправлять уведомлениеPending– промежуточное состояние, когда он собирает данные
В поле for мы можем указать, как долго он будет в состоянии pending. Иначе говоря, как быстро графана будет считать, что действительно что-то случилось, и что она должна отправить нотификацию.
Для теста заменю здесь стандартные 5m на 30s.
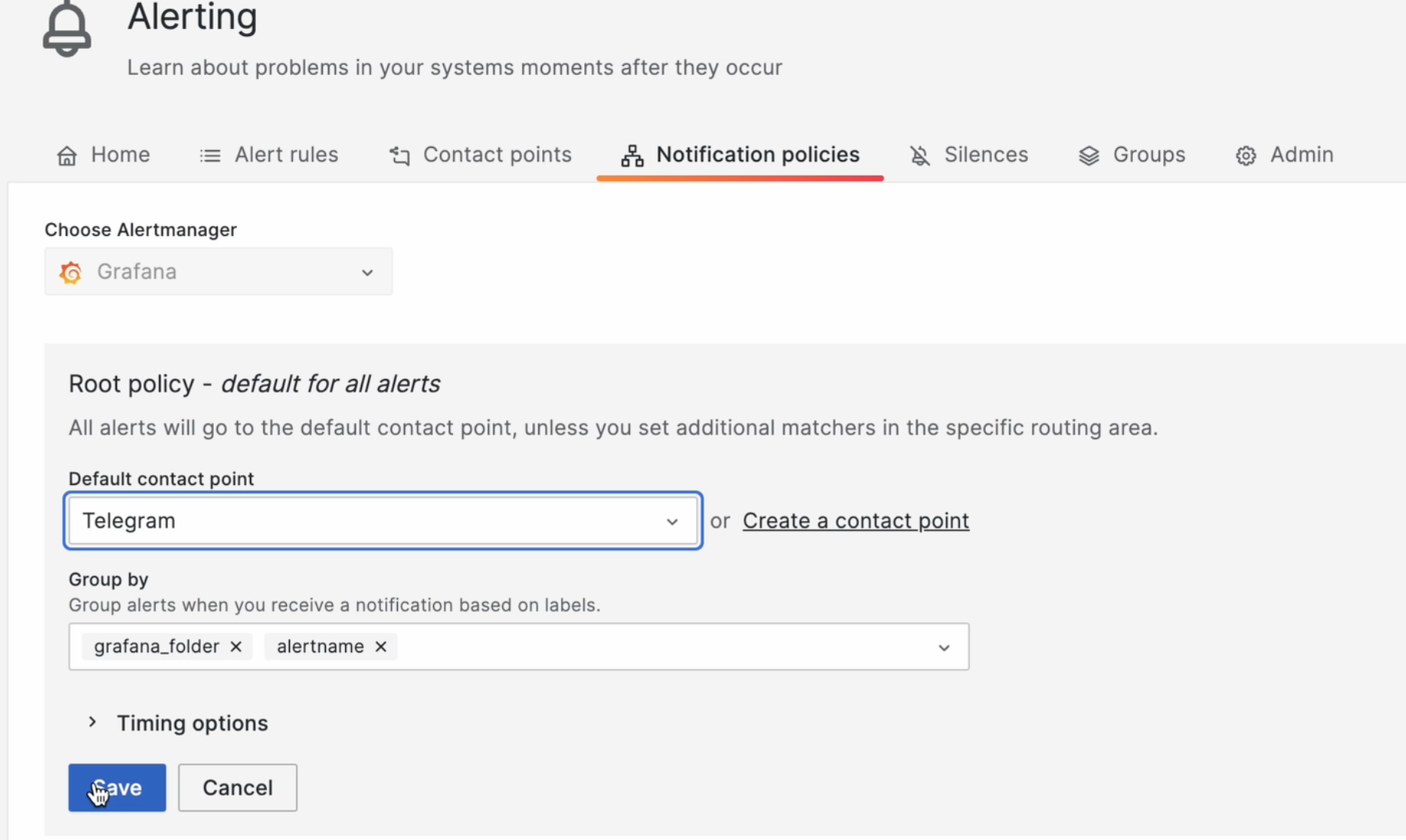
Прежде, чем будем гасить ротатор, давайте перейдем вновь в настройки алертинга и укажем политику, при которой у нас будут отправляться уведомления. Подректируем мы как раз дефолтную политику, применяемую для всех алертов. В ней в качестве дефолтного канала связи выберем Telegram:
Теперь останавливаем работу одного из инстансов и немного ждём. С этого момента прометеус будет фиксировать, что наш сервис упал. Поскольку проверка у нас происходит каждые 10 секунд, то графана говорит, что мы ещё в ожидающем состоянии:
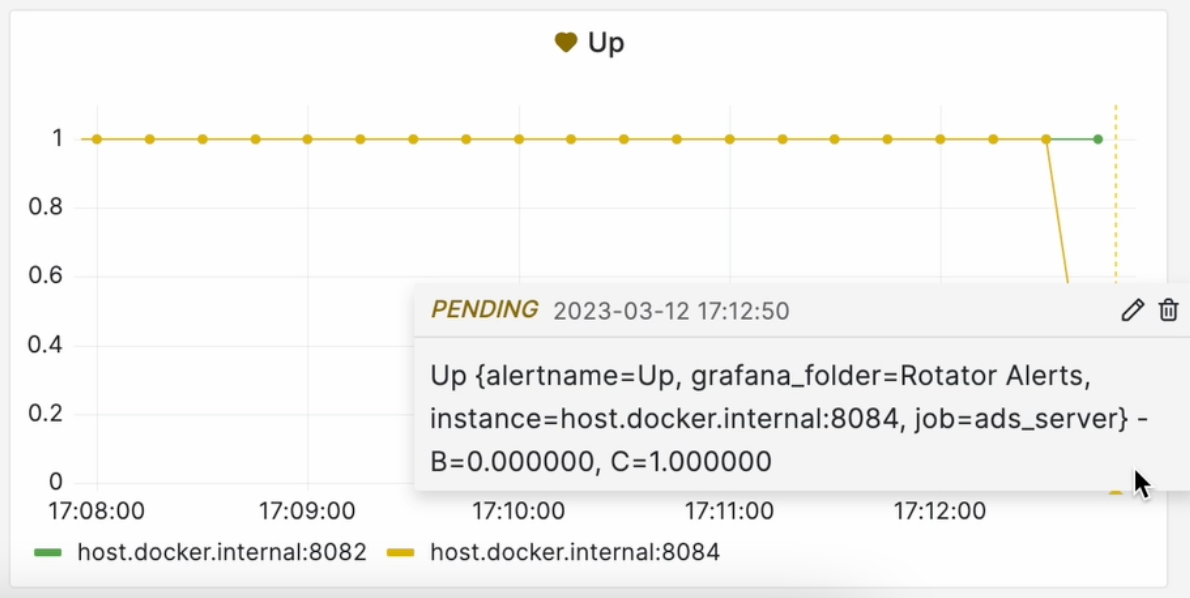
Pending нужен, чтобы не засорять ваш канал с алертами. Может быть такое, что либо, в лучшем случае, случился ложноположительный алерт, либо ваша система может сама пытаться перезапуститься для восстановления.
Именно для таких случаев вы и выжидаете немного времени для того, чтобы система имела возможность восстановиться самостоятельно. Если в течение этой задержки всё восстановится, алерт отправлен не будет. Но если она не восстановится, тогда уже будут затронуты все каналы связи. Например, как у нас сейчас:
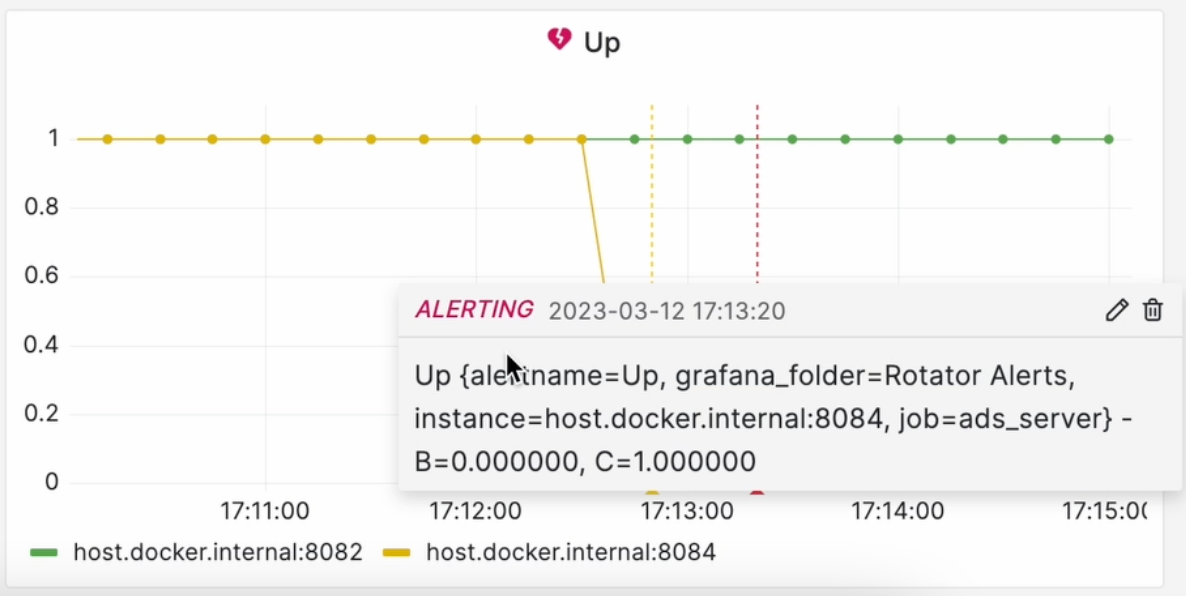
Переключаемся на Telegram канал и, - Вуаля! Вот и наш алерт:

Если мы запустим всё заново, инстанс проснулся и мы видим Ok:
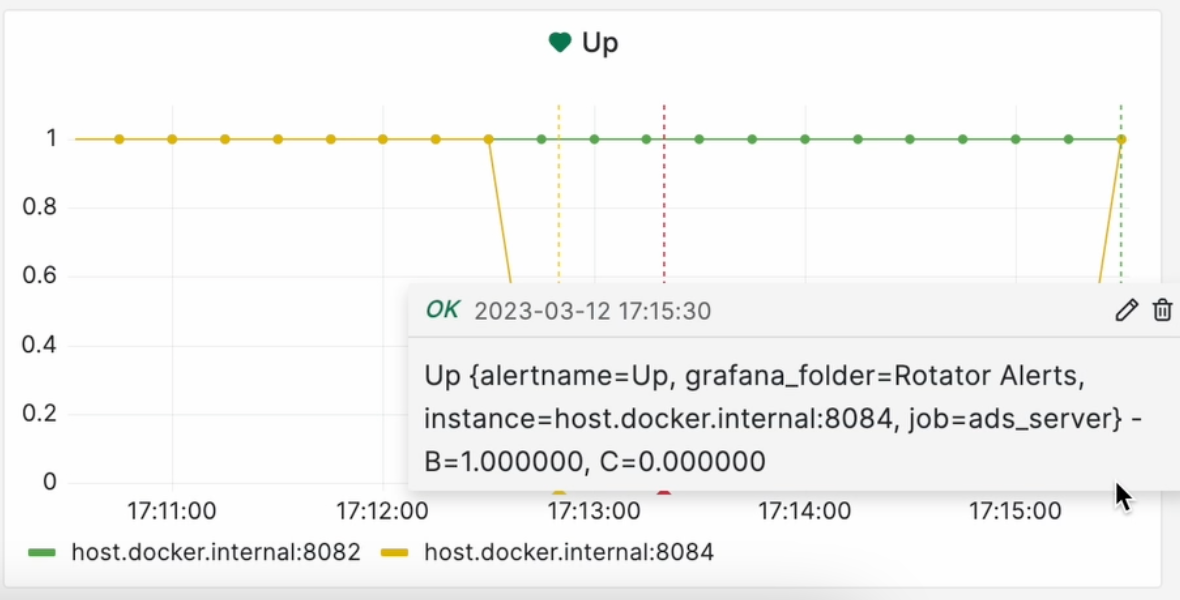
А графана в свою очередь прислала сообщение, что всё отрезолвилось:

Но знаете ли вы, что можно мониторить не только эти скучные системные показатели?
Конечно же, буквально по тому же принципу вы можете навесить алерты и на кликхаус, и мониторить, например, количество денег в статистике в минуту.
Достаточно лишь превратить ваш бизнес-показатель в панель в графане, и вы с лёгкостью навесите алерты и на него. А разными каналами алертинга или contact pointами вы сможете одни алерты направить в один чат, а другие – в другой.
Заключение
Графана – невероятно гибкая и мощная система визуализации. Она покрывает потребности как умного дома, так и какого-нибудь огромного гео-распределённого кластера.
Огромное спасибо за то, что дочитали до конца, удачи вам и прозрачной работы вашим микросервисам!