
Этот выпуск подкаста GoLang Awesome будет особенно интересен GoLang разработчикам, потому что мы с головой окунёмся в специфику работы мап, поймём как они хранятся в памяти, и какие есть библиотеки, упрощающие конкурентную работу с ними. Начинаем погружение.
Что вообще такое “мапа” или “хеш мапа”?
Это структура данных, которая позволяет использовать вместо целочисленных индексов какие-либо хешируемые структуры, вроде строки. И для полного понимания мап давайте вернёмся ещё немного, и поговорим про классические массивы.
Как данные хранятся в массивах?
Максимально просто – в виде региона памяти, который поделён на какое-то количество частей. Количество частей – это размер массива. А размер одной части равен размеру структуры, которая хранится в массиве. Когда вы по индексу обращаетесь, например, к пятому элементу, то на самом деле происходит умножение вот этого индекса на размер структуры. Если результат этого умножения сложить с адресом первого элемента, то как раз и получится адрес пятого. Это называется арифметика указателей.
И по сути всё, мы разобрались, как хранятся элементы в массиве. В случае с чуть более сложными списками, слайсами или листами всё происходит абсолютно также, только небольшая обёртка кода в нужный момент увеличивает размер массива внутри.
Когда вам достаточно индекса, чтобы достать нужное из массива, и вы этот индекс знаете, то вы счастливчик, потому что эта операция максимально быстрая и незатратная. Сложнее, когда вместо числа у вас строка или даже целая структура. Если в этом случае вы упорно продолжаете хранить данные в массиве, то вы сталкиваетесь с задачей поиска индекса. И либо вы ищите линейно, тогда скорость доступа к элементу увеличивается вместе с ростом количества этих элементов, либо вы чуть хитрее, и применяете какой-либо алгоритм, вроде бинарного поиска. Но в любом случае заветного O(1), то есть константного времени доступа вы не получите. И тут на помощь и приходят мапы.
Как данные хранятся в мапах в Go?
Основа любых хеш мап, как вы понимаете, это хеш, который вычисляется из ключа.
Напомню, что хеш или хеш-функция – это преобразование произвольных данных в число, строку или что-либо ещё фиксированной длины, что и будет называться хешем этих данных. Важно, что для одних и тех же входных данных будет всегда одинаковый хеш, то есть, будет соблюдаться принцип “детерминированности”. Но наоборот такого не будет, потому что диапазон входных данных условно неограничен, а диапазон значений хеша ограниченный. В этом случае для двух разных входов может получиться одинаковый хеш, что будет называться “коллизией”.
Так вот, в случае хеш мап для нахождения адреса значения в памяти нужно вычислить хеш ключа. Ключом, соответственно, может быть то, из чего этот хеш посчитать возможно. Например, из строки. И, грубо говоря, хеш и может являться адресом элемента. Если говорить чуть нежнее, то скорее с его помощью мы этот адрес и вычислим. Ведь хешем одного значения может являться число 1234, хешем другого 4321. А у нашей мапы есть конкретный диапазон памяти, где она хранится. И в этом диапазоне нам нужно найти конкретный адрес. Но как?
Для этого гошка делит диапазон памяти мапы на регионы или Bucketы. Количество бакетов всегда соответствует числу со степенью двойки, то есть их либо два, либо четыре, восемь, шестнадцать и так далее. Это специальная хитрость, которая позволяет осуществить определённые побитовые операции для поиска нужного бакета.
Так вот, чтобы определить бакет, в котором может находиться значение полученного ключа, происходит вычисление остатка от деления хеша на количество бакетов. А для ускорения вычислений всё это приправлено побитовыми операциями.
Итак, мы нашли какой-то бакет. Что делать дальше? Надо понять есть ли в найденном бакете нужный ключ. Для этого мы можем перебрать все ключи в бакете, ведь их ещё и ограниченное количество – восемь штук. Но это довольно тяжёлая операция, поэтому в каждом бакете есть, так называемый, массив “топ хешей”.

В нём содержатся старшие биты хешей хранимых ключей. Если старший бит совпал, то ура, возможно запрашиваемый ключ есть в бакете. По номеру найденного хеша достаём ключ из бакета, сравниваем с тем что было запрошено, и возвращаем значение, если всё совпало. Если не совпало, то просто идём дальше по бакету.
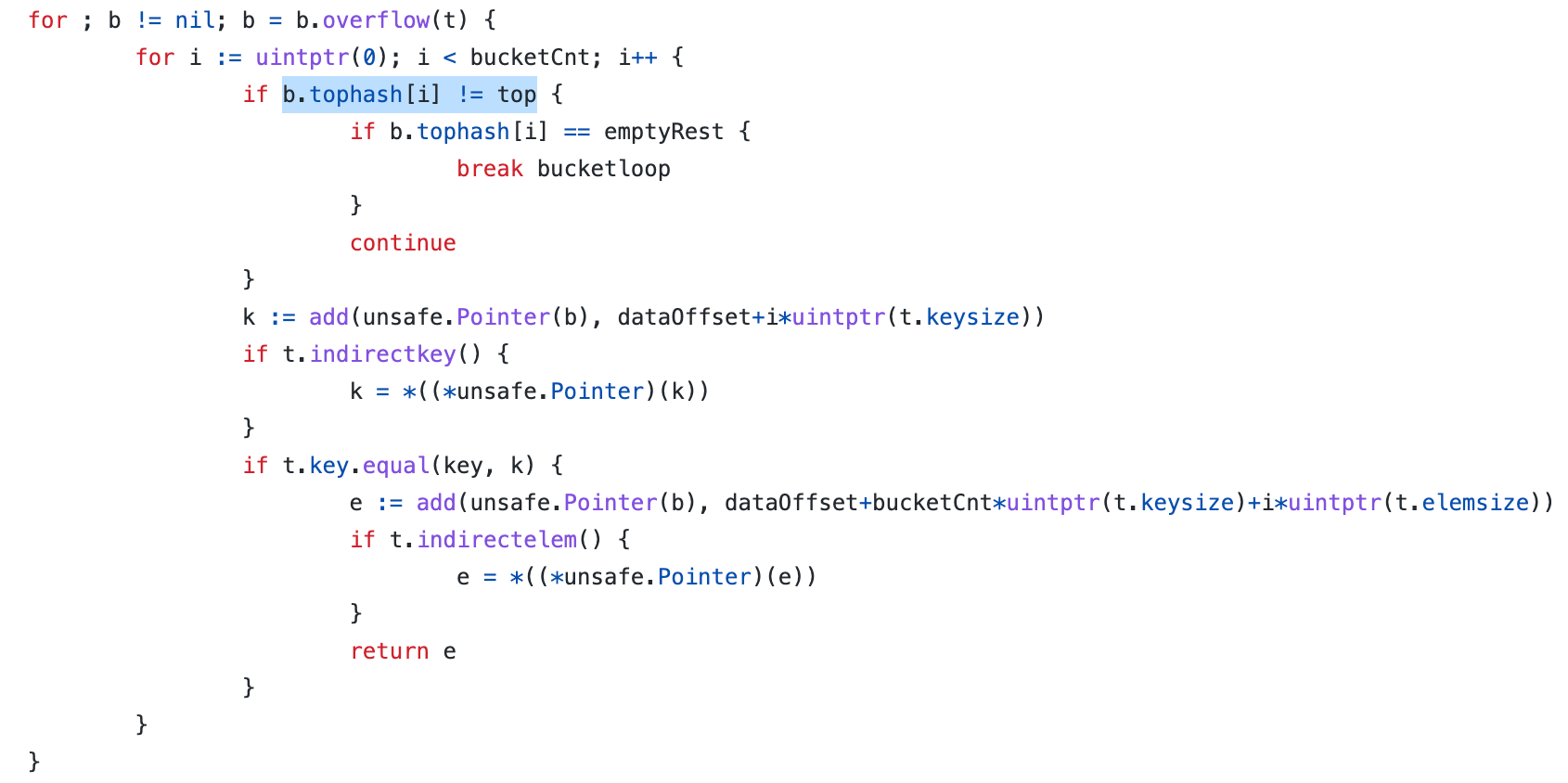
На самом деле, мы можем копнуть ещё больше в технические подробности, но этот подкаст я стараюсь делать больше понятным, чем подробным. Но если вы хотите прям с картинками, деталями и исходниками Go понять, как работают мапы, то советую посмотреть видео моего коллеги Николая Тузова, в котором Николай супер подробно рассказывает про мапы в Go.
Я сам многое брал из его ролика, и рекомендую посмотреть его и вам. Если что, Николай ничего не знает ни про этот подкаст, ни скорее всего про меня, поэтому это не реклама.
И давайте немного подытожим про устройство мап в Go.
- У каждой мапы есть набор бакетов
- За счёт вычисления хеша ключа мы легко можем определить конкретный бакет, в котором можно найти нужное значение
- Каждый бакет может хранить до восьми элементов
- Но чтобы не проходиться по каждому и не сравнивать ключ, у бакета есть массив топ-хешей, по которым мы можем понять есть ли запрашиваемый ключ в бакете
Согласитесь, реализация мап – это произведение искусства с кучей каких-то особенностей и ухищрений. Но иногда и для прекрасного можно найти какие-то особые варианты использования.
Библиотека maps
Например, существует библиотека maps, которая предоставляет разные удобные обёртки для мап, которые можно менять простой заменой типа в коде. Какие именно обёртки?
- Например, обёртка для упорядочивания мапы. Стандартная всегда обходится в случайном порядке. Но если вы хотите иметь предсказуемый порядок, то в библиотеке maps есть тип SliceMap
- Либо обёртка SafeMap для безопасного многопоточного доступа к мапе. Внутри это просто мапа и мьютекс. Для более продвинутого конкуретного доступа без затрат на блокировки есть другая библиотека с названием cmap
Библиотека cmap
Стандартная мапа в Go не защищена от конкурентного доступа. И либо вы спасаетесь обёрткой SafeMap из предыдущей библиотеки, либо блокировки в вашем случае слишком дорогие.
Тогда, в целом, вы могли бы воспользоваться стандартной sync.Map, к которой можно обращаться одновременно. Но стандартная sync.Map больше спроектирована для сценариев, когда, грубо говоря, ключ один раз пишется и много раз читается (append-only). Если же вы используете мапу как in-memory кеш, и у вас, например, часто происходят операции удаления ключей, то cmap может оказаться более быстрым вариантом.
У библиотеки аж 3.5к звёздочек, а последний коммит был совсем недавно – в ноябре.
И на этом я, пожалуй, закончу. Спасибо, что слушаете, смотрите или читаете, оптимизированных приложений вам, и удачи!
Не забудьте посмотреть исходный код типа map в репозитории GoLang.