8 критериев для выбора PUSH или PULL мониторинга, push-gateway в Go

Мониторинг – важная часть любого микросервиса на Go. Но мониторинг бывает разным. Как выбрать подходящий? Стоит начать с выбора модели мониторинга: push или pull.
И в этом видео я расскажу про восемь критериев, по которым вы сможете оценить ваше приложение и выбрать правильную модель мониторинга: активную или пассивную, а затем и конкретную систему мониторинга.
А если вы выбрали Prometheus, но хотите пушить в него метрики, то я покажу как пользоваться push-gateway для использования push модели с pull-ориентированным Prometheus.
Критерии
1. Время жизни приложения
Бывают долгоживущие приложения – вроде какого-либо сервера (например, рекламного). А бывают короткоживущие, когда приложение запускается, что-то делает и завершается. Например, импортирует данные статистики партнёра.
Если приложение долгоживущее, то можете смело использовать оба подхода.
А если короткоживущее, то вам открыт путь лишь до Push модели.
2. Связность приложения и сервиса метрик
В случае Pull модели приложение и сервис метрик связаны минимально: приложение экспортирует произвольные метрики, система мониторинга их пуллит и сохраняет. Вопрос сбора метрик решается полностью за пределами программы.
А в Push модели приложение должно знать куда отправлять метрики, иметь авторизационные ключи и так далее. При этом система мониторинга знает какие метрики будут поступать.
3. Доступность сервера снаружи (NAT)
Для Pull модели система мониторинга должна иметь возможность “достучаться” до приложения. Если оно за NATом, то использовать Pull становится сложно, ведь нужно как-то прокидывать порт. Другой пример: мобильное приложение, вы ведь никак не обратитесь напрямую к устройствам пользователей.
У Push модели ситуация обратная и от этого более простая: достаточно добиться доступности центральной ноды с приложений.
4. Безопасность
Для Pull модели есть много тонкостей, которые нужно не упустить:
- Желательно установить реверс-прокси, вроде nginx, чтобы запросы не шли напрямую в приложение
- Нужно не забыть закрыть порт nginx хоста в файрволле для всех, кроме сервера мониторинга
- Нужно не забыть настроить экспортёр так, чтобы его порт прослушивался только на
127.0.0.1(если вы используете реверс-прокси)
У Push модели всё проще и от этого безопаснее: главное, “защищаете” центральную ноду так, чтобы только приложения могли к ней пробиться, и больше ничего “открывать” не нужно.
5. Развёртка (деплой) на конечный сервер
У Pull модели, как я писал выше, желательно установить и настроить реверс-прокси, настроить файрволл и сам экспортёр.
А у Push модели достаточно прописать хост центральной ноды и данные доступа.
6. Обнаружение недоступности ноды
У Pull модели в этот раз ситуация проще: вы максимально быстро узнаёте о недоступности, и у вас есть конкретные симптомы: соединение рвётся, таймаутит или nginx отдаёт 5XX ошибку.
У Push модели придётся немного покопаться и выяснить конкретную причину: упал агент, весь сервер, неполадки с сетью или приложение вообще переехало.
7. Централизованная настройка
У Pull модели все настройки, таргеты, частоты опроса хранятся в одном месте – на центральном сервере. Вы даже можете сделать необходимые трансформации данных (recording rules).
У Push модели, как правило, данные о необходимых метриках раздаются с центральной ноды. Также, вам необходимо позаботиться о том, как доставить авторизационные ключи и настройки подключения в конфиги агентов.
8. Масштабирование
У Pull модели стратегия сводится к установке всё более мощной центральной ноды, а когда дальнейший апгрейд становится неэффективным, то применяют горизонтальное масштабирование. Например, у Prometheus есть механизм federation, когда одна нода может стянуть данные с другой. Можно строить схемы “приложение → региональный Prometheus → центральный Prometheus”.
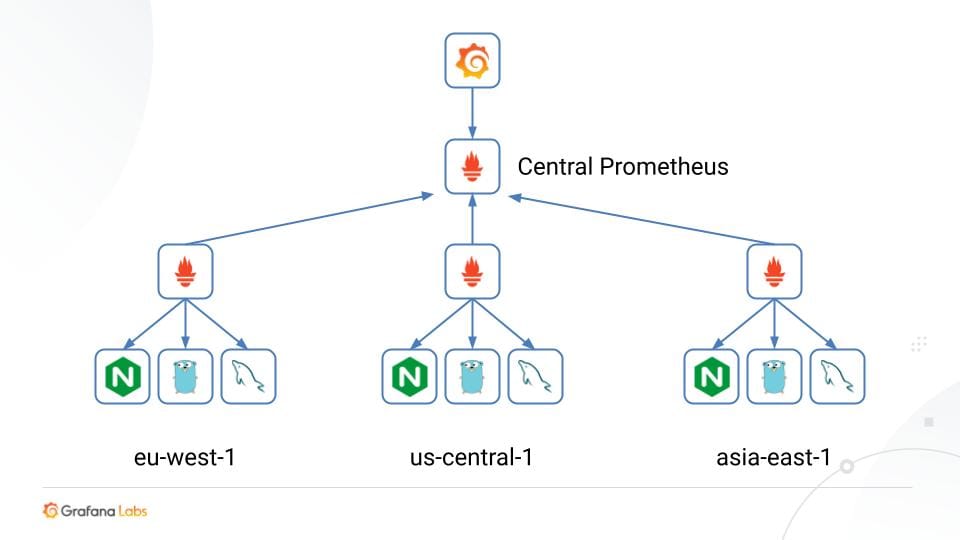
У Push модели всё несколько проще, потому что агенты по определению распределены по нодам, и обычно нагрузка на центральную ноду всё равно меньше, чем при пуллинге. Но если мощностей перестаёт хватать, то у Zabbix, например, есть прокси для горизонтального масштабирования.
Работа с push-gateway
Допустим, вы выбрали Prometheus, и Вам он полностью подходит. Но что делать, если появилось необходимость в него метрики пушить? Не ставить же ради этого заббикс.
Для этого существует push-gateway. Он делает возможным пушить метрики прямо в него, а Prometheus затем заберёт их по pull модели.
Стоит упомянуть, что превращать Prometheus в Push систему мониторинга не стоит, потому что вы рискуете столкнуться с такими последствиями:
- Невозможность мониторить “живость” инстанса через метрику
up(мы ведь больше не “дёргаем” его) - Сам
push-gatewayстановится дополнительной точкой отказа в общей цепочке - Метрики, однажды отправленные в
push-gateway, не удалятся автоматически. Он их сохранит и будет отдавать прометеусу до тех пор, пока вы их явно не удалите
Подробнее можете почитать в официальной доке. Но если у вас весь кластер на Pull модели, и появились некие Jobы (короткоживущие приложения) – то push-gateway будет очень полезным.
Давайте установим и воспользуемся им.
1. Установка push-gateway
Я человек ленивый, поэтому подниму инстанс через Docker.
docker-compose.yml:
version: "3"
services:
prometheus:
image: prom/prometheus:v2.44.0
volumes:
- ./prometheus.yml:/etc/prometheus/prometheus.yml
ports:
- "19090:9090"
pushgateway:
image: prom/pushgateway:v1.5.1
ports:
- "19091:9091"
Стоит также не забыть и про prometheus.yml, и у меня он будет максимально стандартным:
global:
scrape_interval: 15s # By default, scrape targets every 15 seconds.
evaluation_interval: 15s # By default, scrape targets every 15 seconds.
# A scrape configuration containing exactly one endpoint to scrape:
# Here it's Prometheus itself.
scrape_configs:
# The job name is added as a label `job=<job_name>` to any timeseries scraped from this config.
- job_name: 'prometheus'
# Override the global default and scrape targets from this job every 5 seconds.
scrape_interval: 15s
scrape_timeout: 15s
# metrics_path defaults to '/metrics'
# scheme defaults to 'http'.
static_configs:
- targets: ['localhost:9090']
# The job name is added as a label `job=<job_name>` to any timeseries scraped from this config.
- job_name: 'push-gateway'
# Override the global default and scrape targets from this job every 5 seconds.
scrape_interval: 15s
scrape_timeout: 15s
# metrics_path defaults to '/metrics'
# scheme defaults to 'http'.
static_configs:
- targets: ['pushgateway:9091']
Поднимаем любимой командой docker compose up, и можем открыть web интерфейс как самого прометеуса, так и push-gateway (да, у него есть веб-интерфейс!).
Как видите, пока никаких метрик не зарегистрировано. Давайте же это исправим!
2. Отправка метрик в push-gateway на Go
Для работы с Prometheus метриками нам понадобится библиотека prometheus/client_golang:
go get -u github.com/prometheus/client_golang
Далее давайте создадим файл job.go, в котором и разместим код воображемой джобы:
package main
import (
"github.com/prometheus/client_golang/prometheus"
"github.com/prometheus/client_golang/prometheus/promauto"
"github.com/prometheus/client_golang/prometheus/push"
"math/rand"
"time"
)
var (
// Создам registry, чтобы затем удобно "объединить" все метрики
myRegistry = prometheus.NewRegistry()
// Создам некую первую метрику.
// Благодаря пакету "promauto" мне не нужно заморачиваться
// с "prometheus.MustRegister(...)", за меня это всё сделает "promauto.With(...)"
myCounter = promauto.With(myRegistry).NewCounter(prometheus.CounterOpts{
Name: "my_metric",
})
// И некая вторая метрика
mySecondCounter = promauto.With(myRegistry).NewCounter(prometheus.CounterOpts{
Name: "my_second_metric",
})
)
func main() {
rand.Seed(time.Now().Unix())
myCounter.Add(float64(rand.Int31n(100)))
mySecondCounter.Add(float64(rand.Int31n(10)))
//делаем что-то долгое
//я запускаю джобу на локальном хосте,
//а порт push-gateway прокидывается на него под IP "19091".
//
//my_job – буквально аналог поля "job_name",
//если бы вы настраивали метрики по pull модели.
if err := push.New("http://127.0.0.1:19091", "my-job").
Gatherer(myRegistry).
Push(); err != nil {
panic(err)
}
}
Затем давайте запустим эту “джобу” командой go run job.go. Можно даже несколько раз, для надёжности (на самом деле данные будут разные благодаря этому).
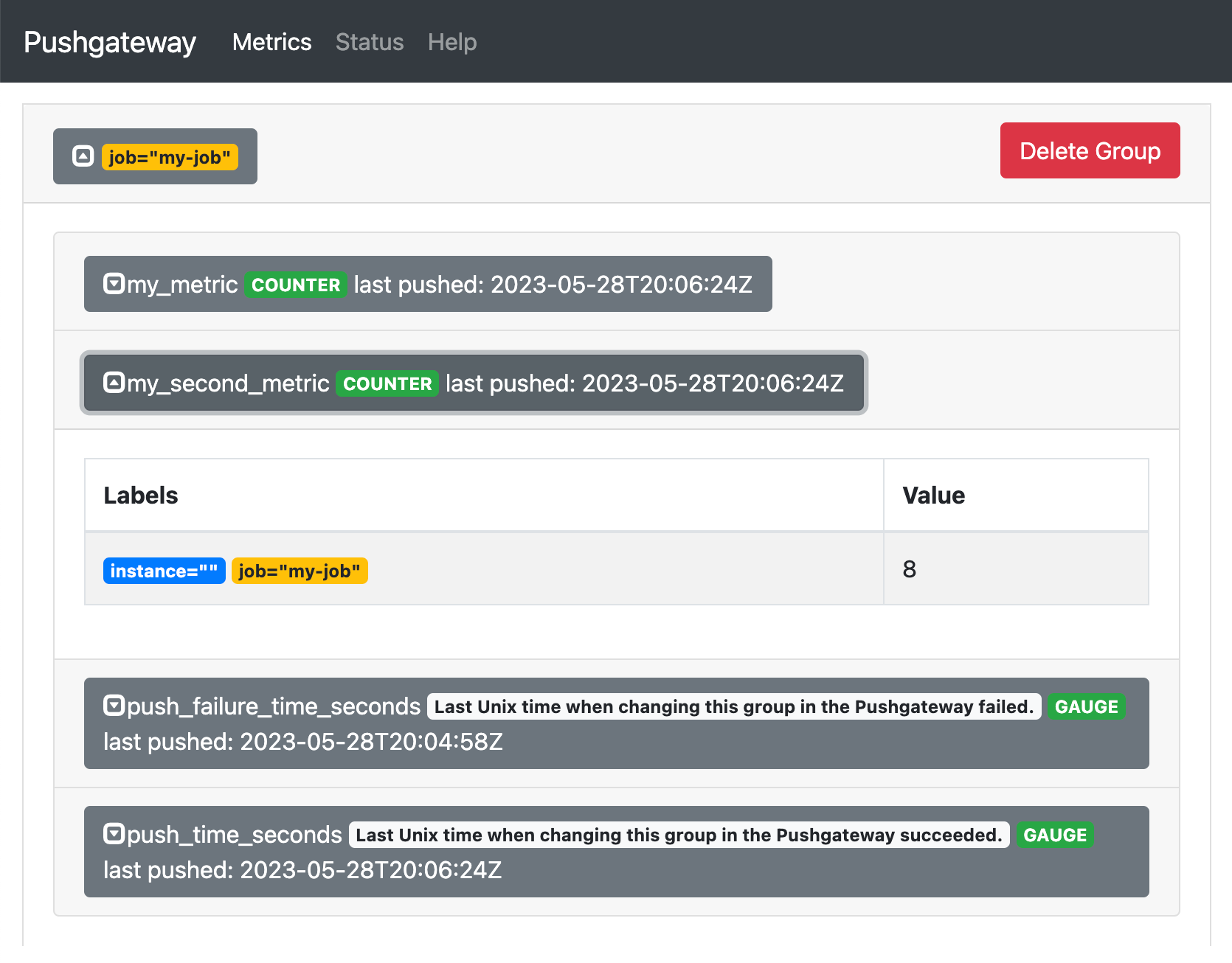
3. Смотрим результат
В интерфейсе push-gateway новые метрики выглядят так:
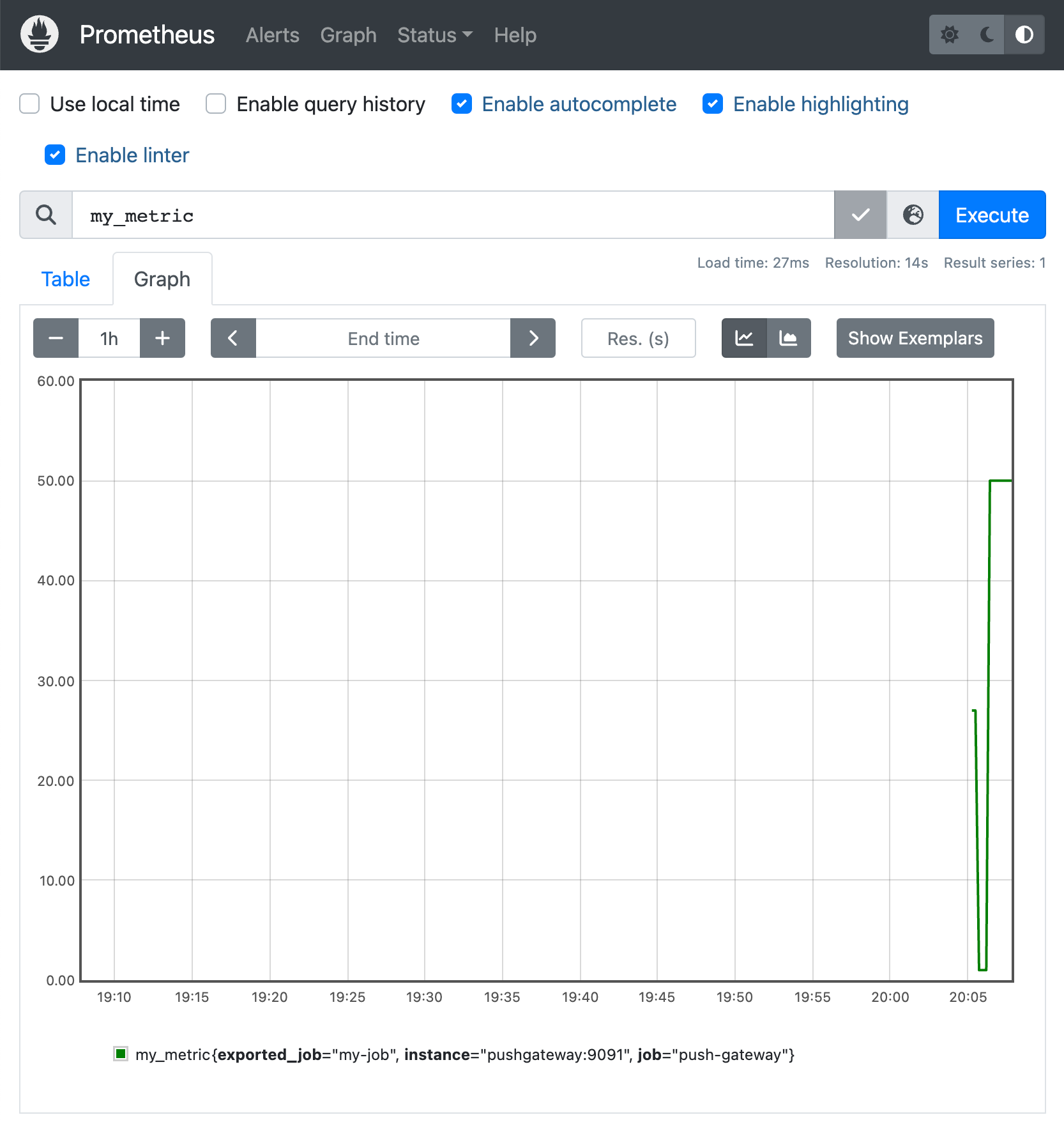
Теперь мы можем вернуться в интерфейс Prometheus, и полюбоваться графиком нашей метрики!
Заключение
Надеюсь, эта статья оказалась для вас полезной. Если так, то загляните на канал на YouTube, подпишитесь и жмякните лайк, мне будет безумно приятно.
А если остались вопросы, то либо пишите их прямо под видео, либо велком в Telegram канал по контактам в футере.
Надёжных приложений вам, и чтобы в up ваш инстанс никогда не был 0!